Day 22 - 머신러닝 3 > KNN(K - Nearest Neighbors)
2022. 11. 9. 17:10ㆍPython
이번 글에서는 머신러닝 알고리즘 중 KNN에 대해 다룰 것이다.
KNN은 선형관계를 상정하지 않은 데이터셋에서도 활용할 수 있는 거리기반 머신러닝 모델로, 다중분류 문제에 적용 가능하다. KNN의 풀네임을 보면 유추할 수 있듯, KNN은 K개의 가장 가까운 데이터에 의해 결과값을 예측하는 알고리즘이다. 이 K값은 사용자가 지정할 수 있다.
K개의 데이터를 하나하나 고려하여 예측하는 알고리즘이다보니, K의 값이 크고 데이터셋의 크기가 클 수록 속도가 느려진다. 따라서 작은 데이터셋에 적합하다. 또한 이상치에 취약하다는 단점이 있다.
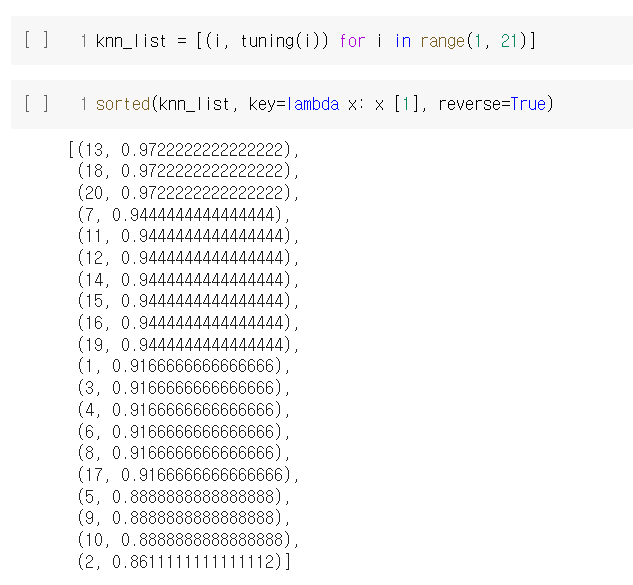
KNN 알고리즘 실습을 wine classification 데이터를 통해 진행했다.



'Python' 카테고리의 다른 글
| Day 22/23 - 머신러닝 4 > 나이브 베이즈 (Naive Bayes) (0) | 2022.11.09 |
|---|---|
| Day 22 - 머신러닝 3 > KNN(K - Nearest Neighbors) (2) (0) | 2022.11.09 |
| Day 21 - 머신러닝 2 > 로지스틱 회귀 (0) | 2022.11.08 |
| Day 20 - 머신러닝 1 > 선형회귀 (0) | 2022.11.07 |
| Day 19 - Titanic 데이터 실습 (0) | 2022.11.02 |