Day 22/23 - 머신러닝 4 > 나이브 베이즈 (Naive Bayes)
2022. 11. 9. 17:25ㆍPython
이번 글에서는 머신러닝 모델 중 나이브 베이즈에 대해 다룰 것이다.
나이브 베이즈는 조건부 확률 기반의 분류 모델로, 스팸 필터링을 위한 대표적인 모델이라고 한다. 나이브 베이즈의 경우 속도가 빠르면서 작은 데이터셋으로도 잘 예측한다는 장점이 있지만, 모든 독립변수가 각각 독립적이라고 전제한다는 단점이 있다. 현실 세계에서 이런 데이터는 드물기 때문에 나름 치명적인 단점이라고 할 수 있겠다.
나이브 베이즈 실습은 SMS Spam Collection 데이터를 통해 진행했다.
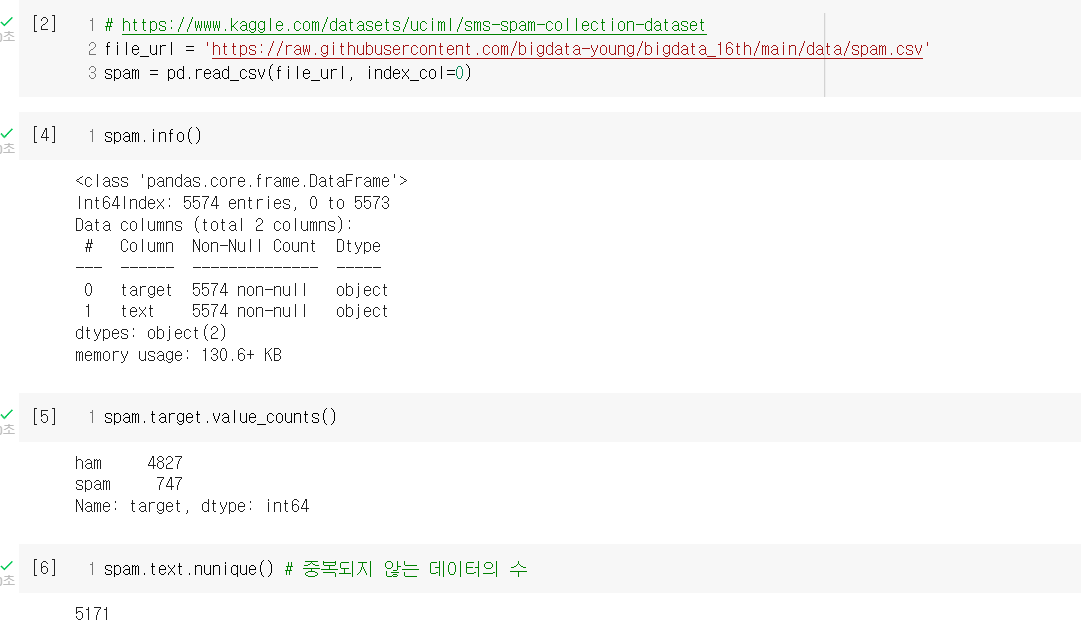
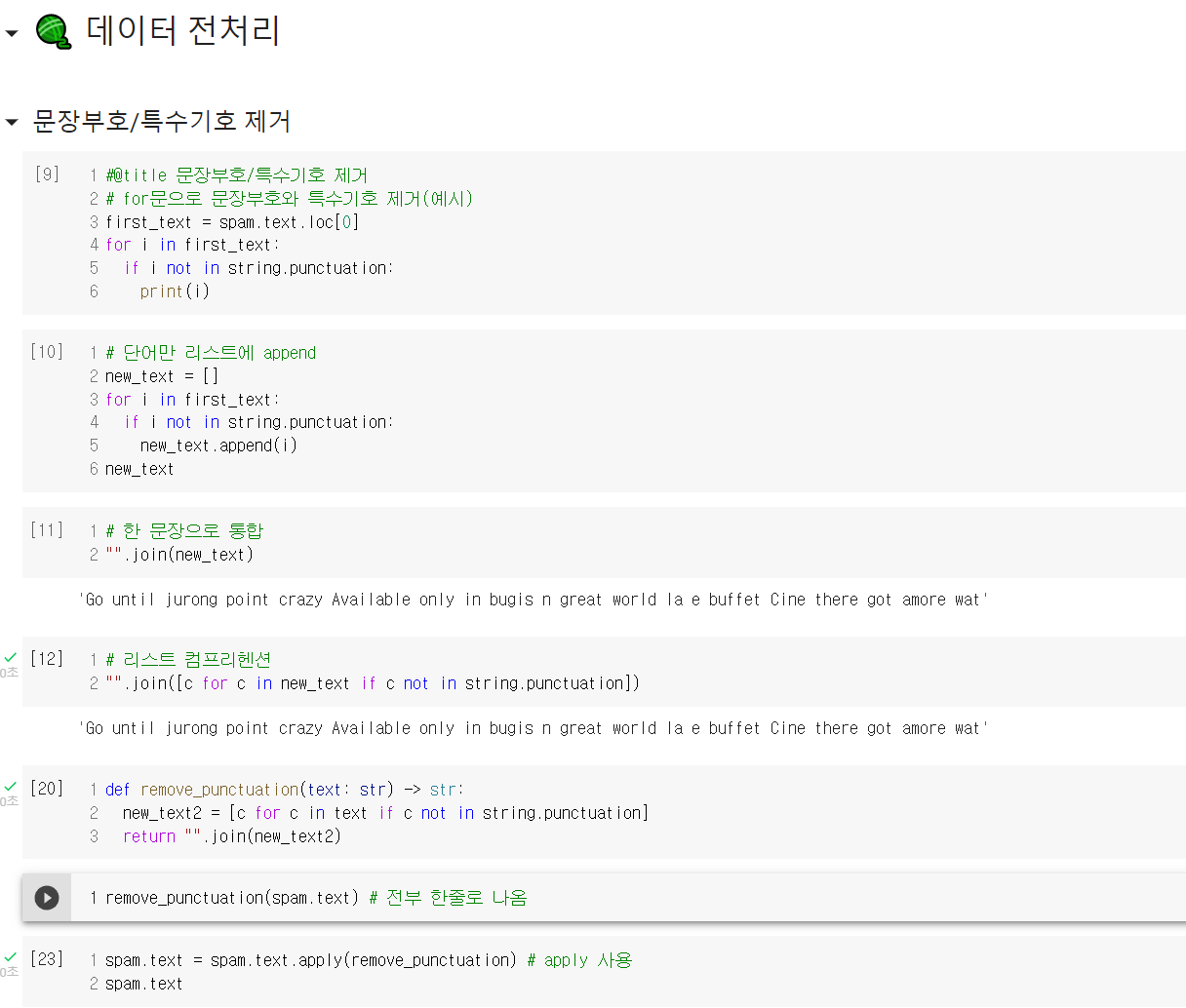
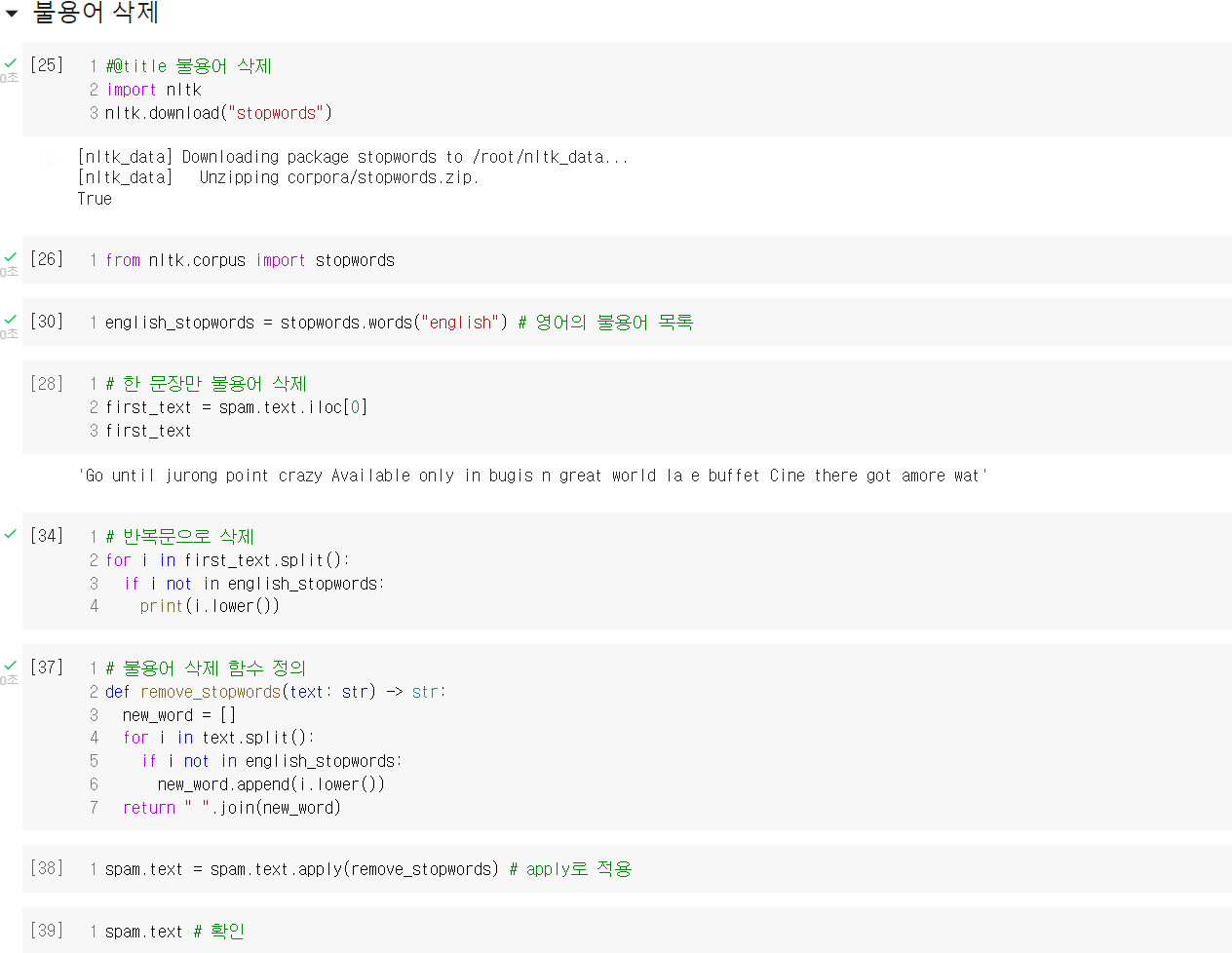



나이브 베이즈 모델 자체의 개념은 조건부 확률의 개념만 명확히 알고 있으면 쉬우나, 언어데이터를 벡터화하는 과정이 전처리에서 추가된다는 점을 잘 알아두어야 겠다. 또한 아무래도 영어가 이런 분석에 있어 연구가 많이 진행되어 더 쉬운데, 한국어로도 나이브 베이즈 모델을 통해 머신러닝 분석을 연습해보는 것도 좋겠다.
'Python' 카테고리의 다른 글
| Day 25 - 머신러닝 6 > 랜덤 포레스트 (Random Forest) (0) | 2022.11.14 |
|---|---|
| Day 23/24 - 머신러닝 5 > 결정 트리 (Decision Tree) (0) | 2022.11.12 |
| Day 22 - 머신러닝 3 > KNN(K - Nearest Neighbors) (2) (0) | 2022.11.09 |
| Day 22 - 머신러닝 3 > KNN(K - Nearest Neighbors) (0) | 2022.11.09 |
| Day 21 - 머신러닝 2 > 로지스틱 회귀 (0) | 2022.11.08 |