2022. 11. 2. 17:18ㆍPython
이번 글에서는 그동안 배운 데이터 전처리와 분석, 시각화를 Titanic 데이터를 통해 실습해 볼 것이다. Hello World!에 비할바는 못되지만 역시 데이터 분석 실습의 첫 걸음은 Titanic 데이터라고 생각한다.

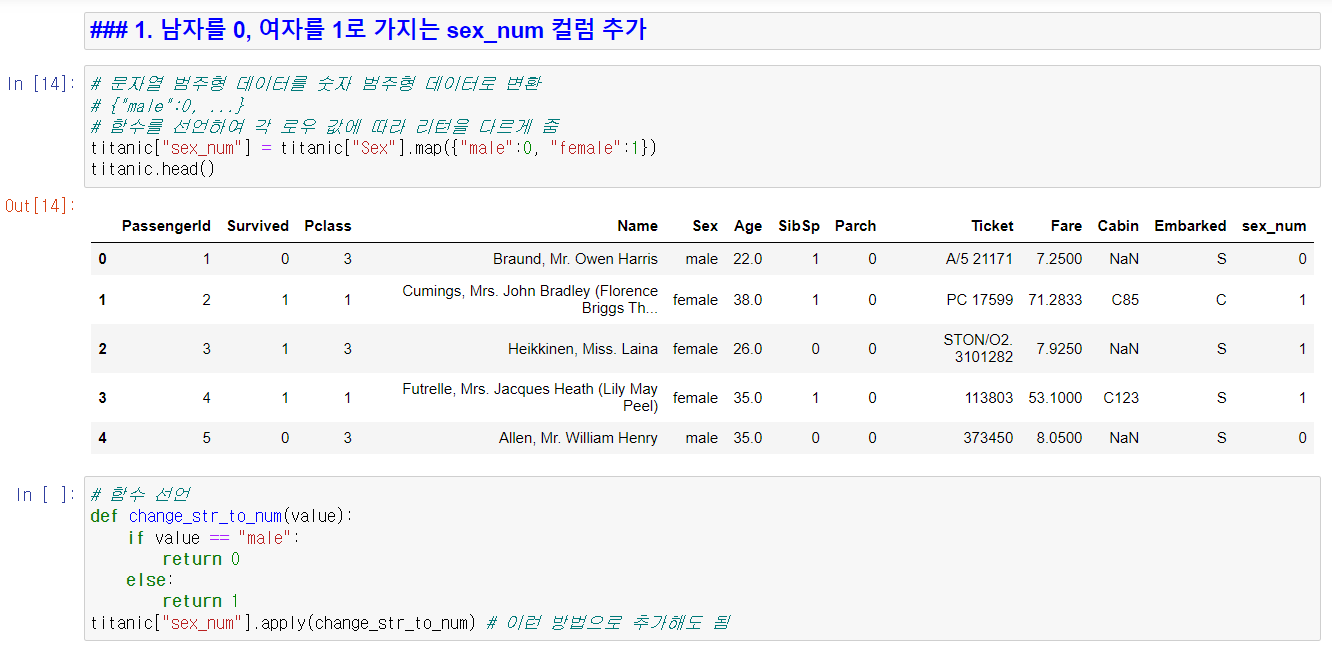
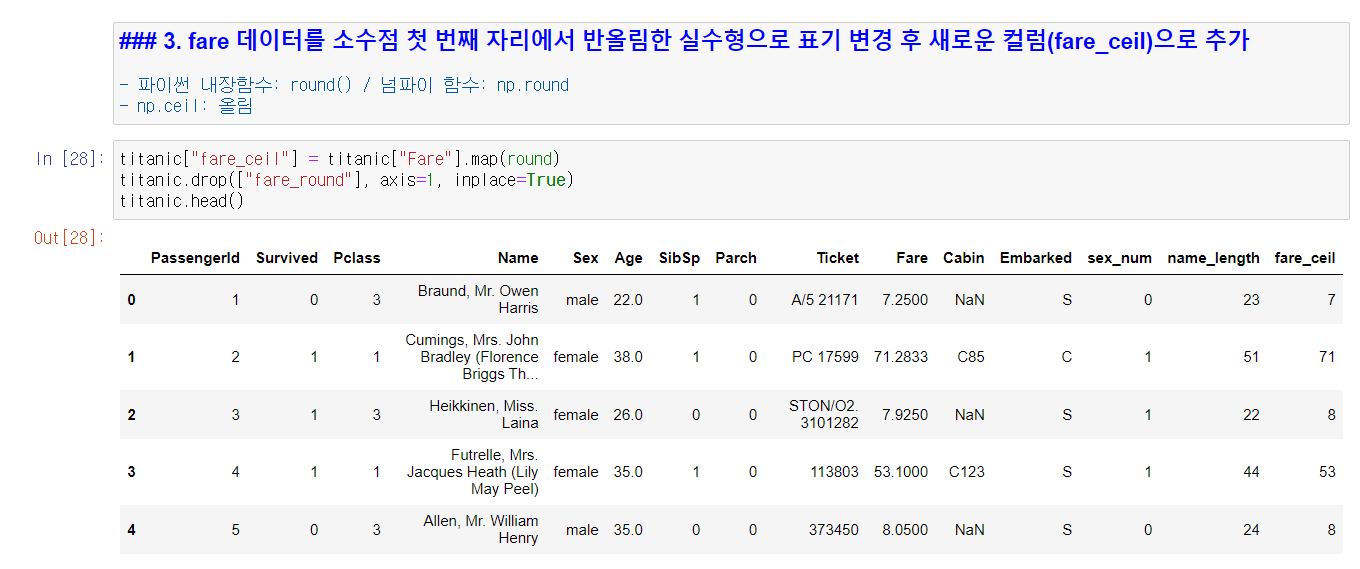
우선, Titanic 데이터를 불러와 Titanic 데이터프레임에 저장하고, 분석하기 이전 더 용이한 분석을 위해 몇 가지 컬럼을 추가했다. 추가한 컬럼은 남녀 성별을 0/1로 구분하는 컬럼, 이름의 길이값을 저장하는 컬럼, 요금을 반올림한 컬럼이다. 우선은 커스텀 함수를 정의하지 않고 기존 함수나 dictionary를 이용하여 컬럼을 추가해보았다.

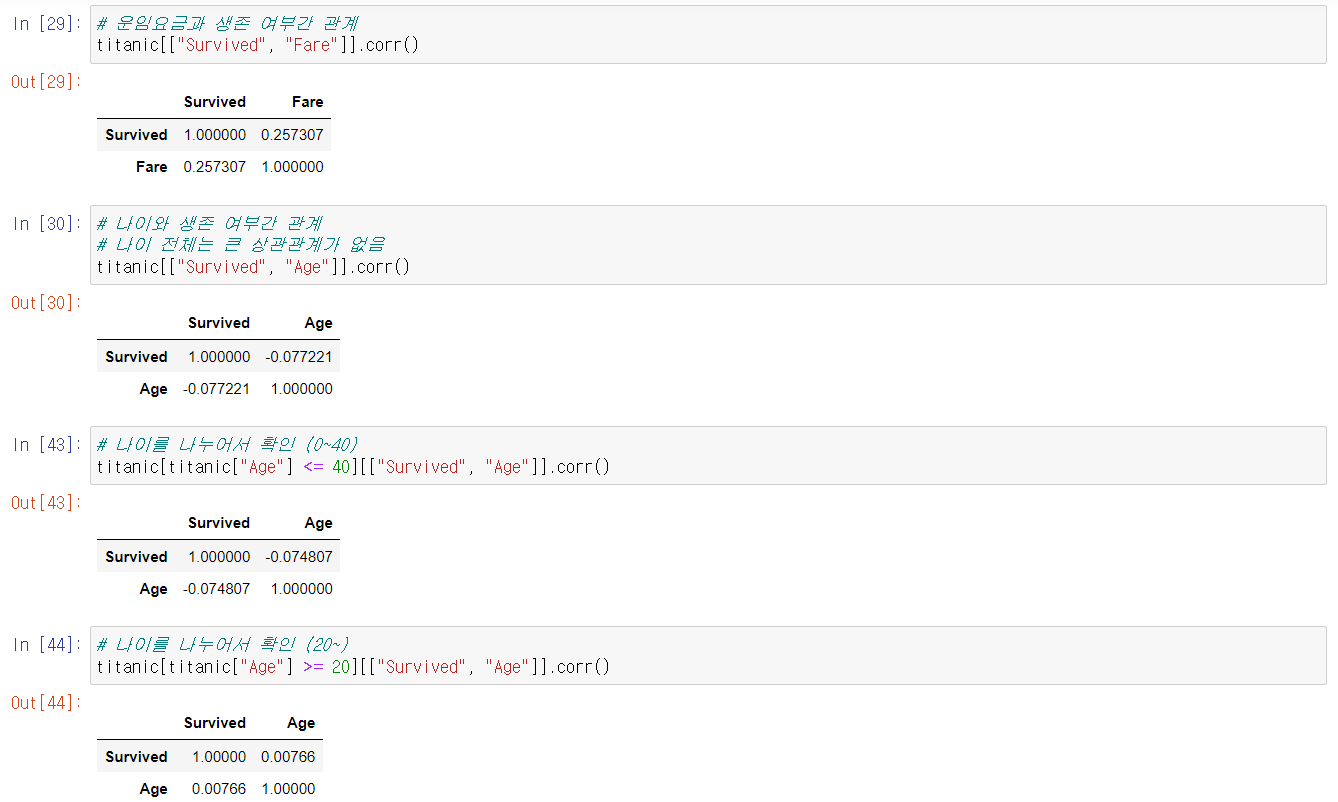
추가한 컬럼과 생존여부 간 상관분석을 진행했다.

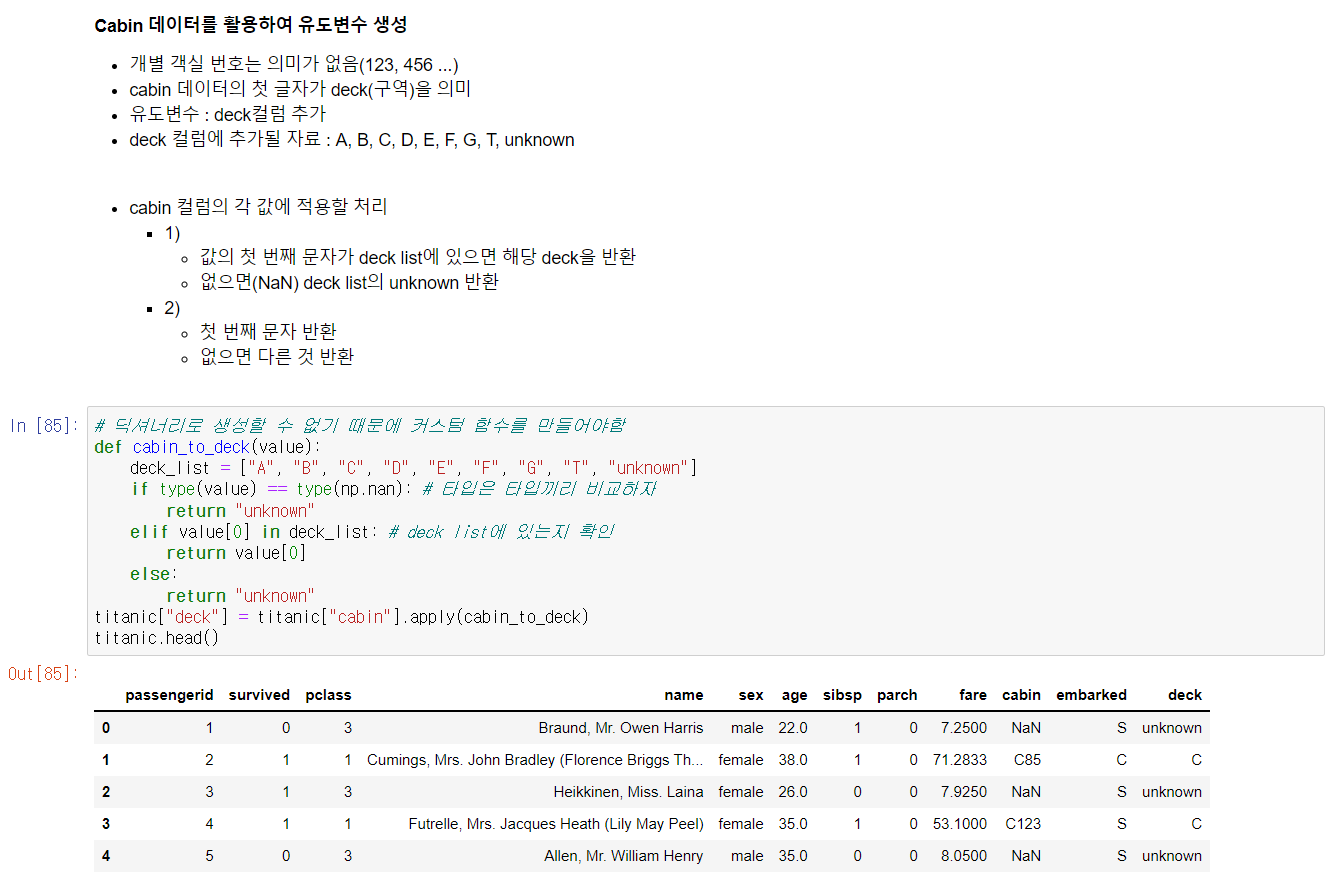
그 뒤 본격적인 분석을 위해 필요한 전처리 과정의 일환인 유도변수 생성에 대해 배웠다. 사실 기본 개념 자체는 성별을 0/1로 나누어 지정하는 것과 비슷하지만, 데이터 수가 많은 경우엔 일일이 dictionary로 지정할 수 없기 때문에 커스텀 함수를 정의하여 유도변수 생성 후 컬럼을 추가했다. 추가한 컬럼은 cabin의 deck만 따로 지정한 컬럼, name의 호칭만 따로 지정한 컬럼 그리고 그 이후 호칭만 지정한 컬럼을 다시 한 번 묶어서 정리한 컬럼이다.

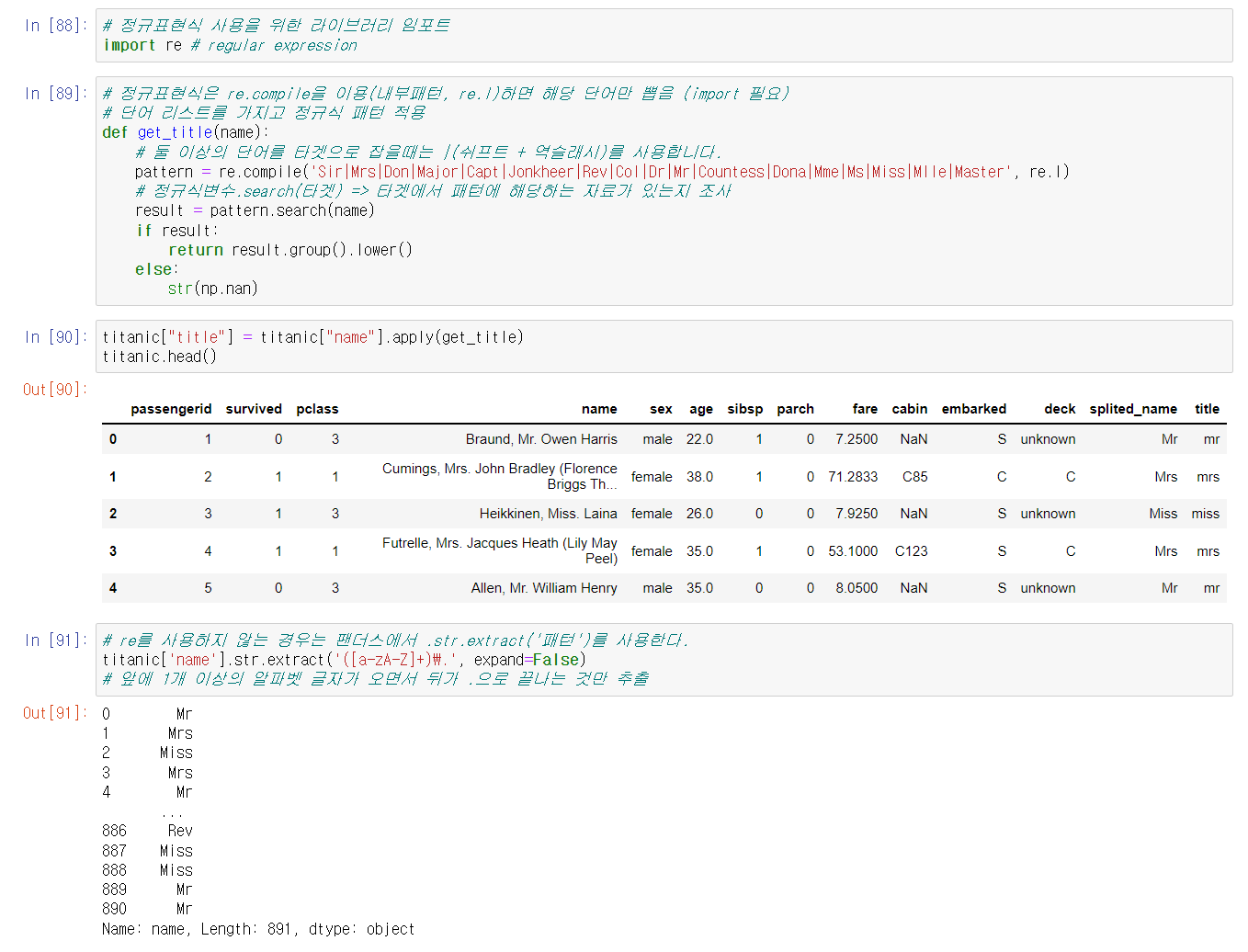
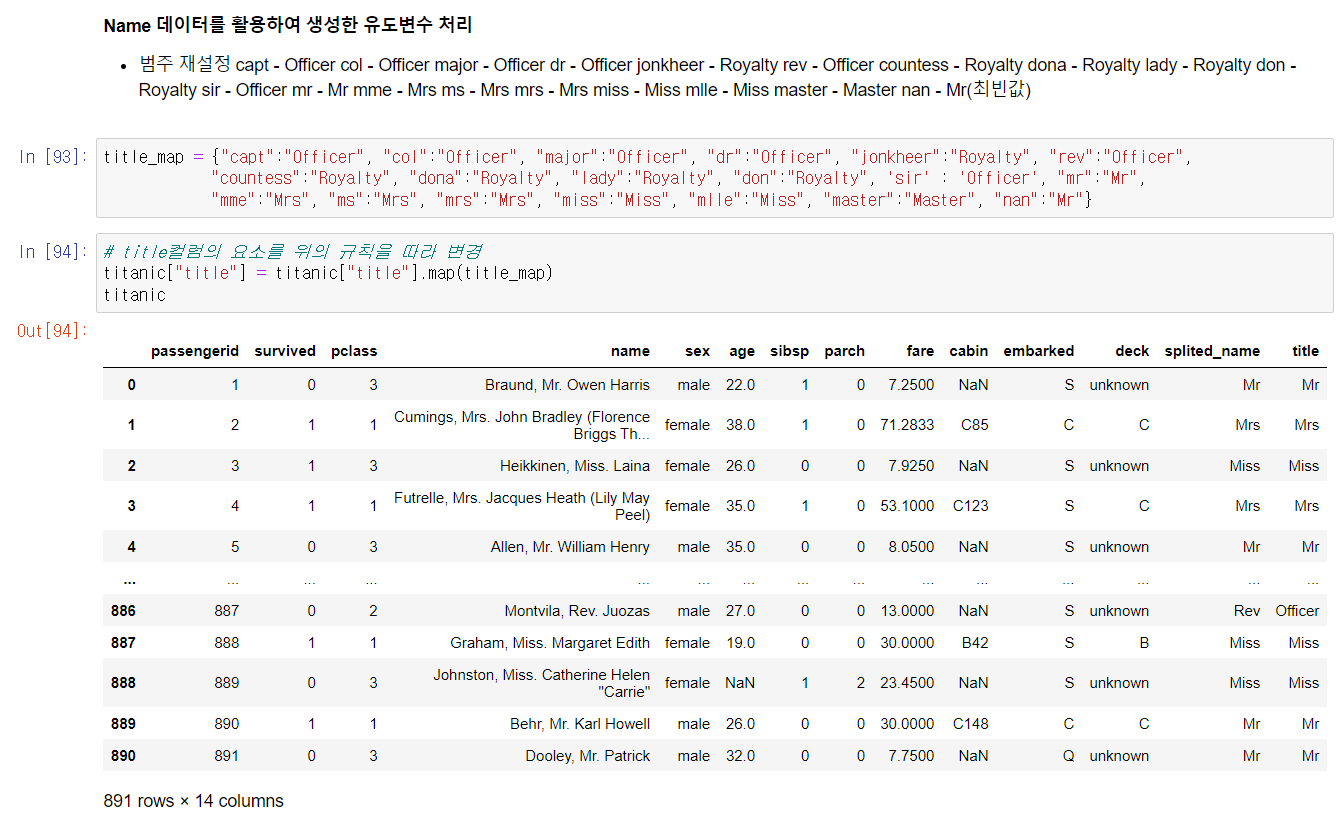
커스텀 함수를 정의할 때, split이나 정규표현식 등을 활용하는 방법에 대해 이해하고 체화하도록 공부해야 겠다.
이후, age컬럼의 결측치 처리를 진행했다. 결측치의 경우 각 호칭 집단 별 평균 연령으로 대체했다.
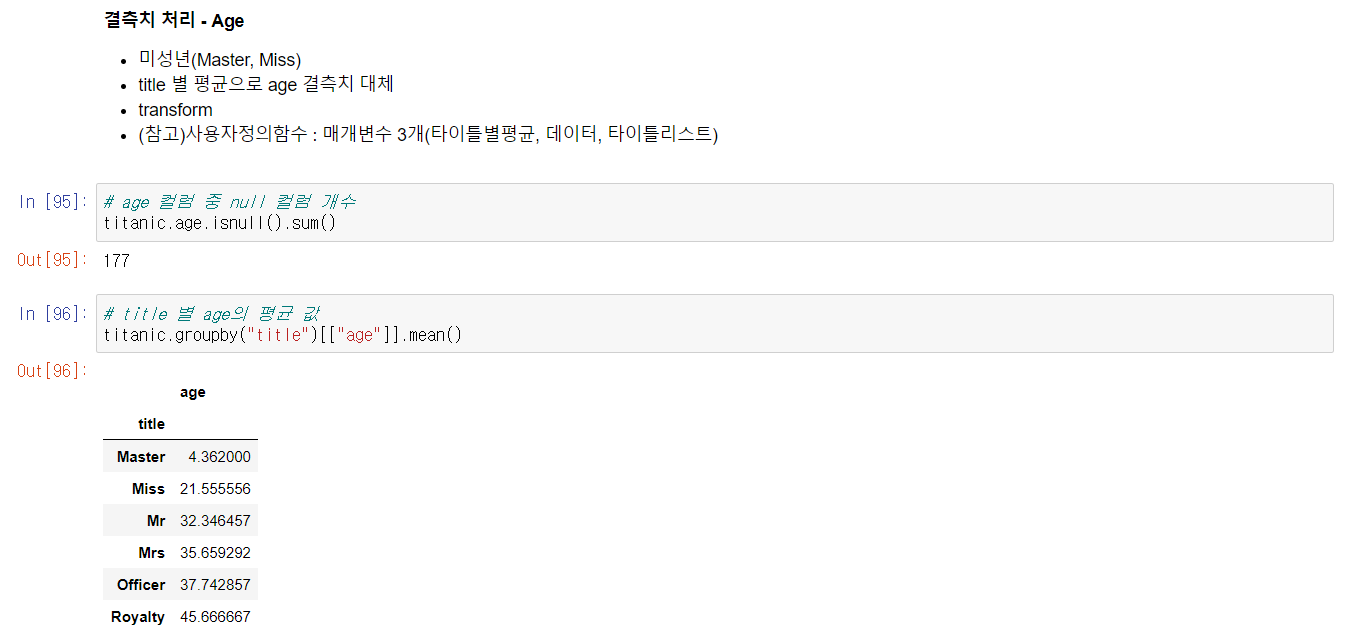
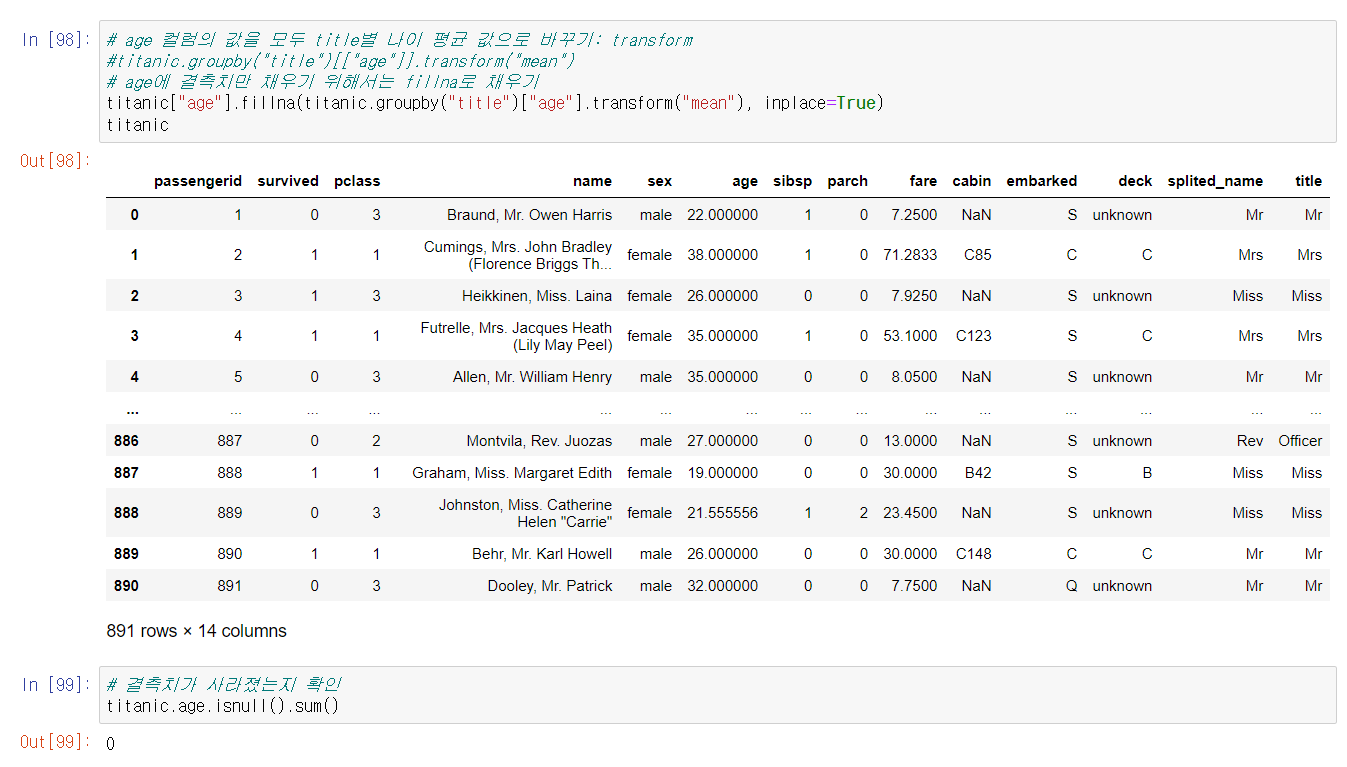
나이 그 자체만으로는 분석에 큰 의미가 없기 때문에, 나이 역시 집단으로 묶어 범주형 데이터로 반환했다.
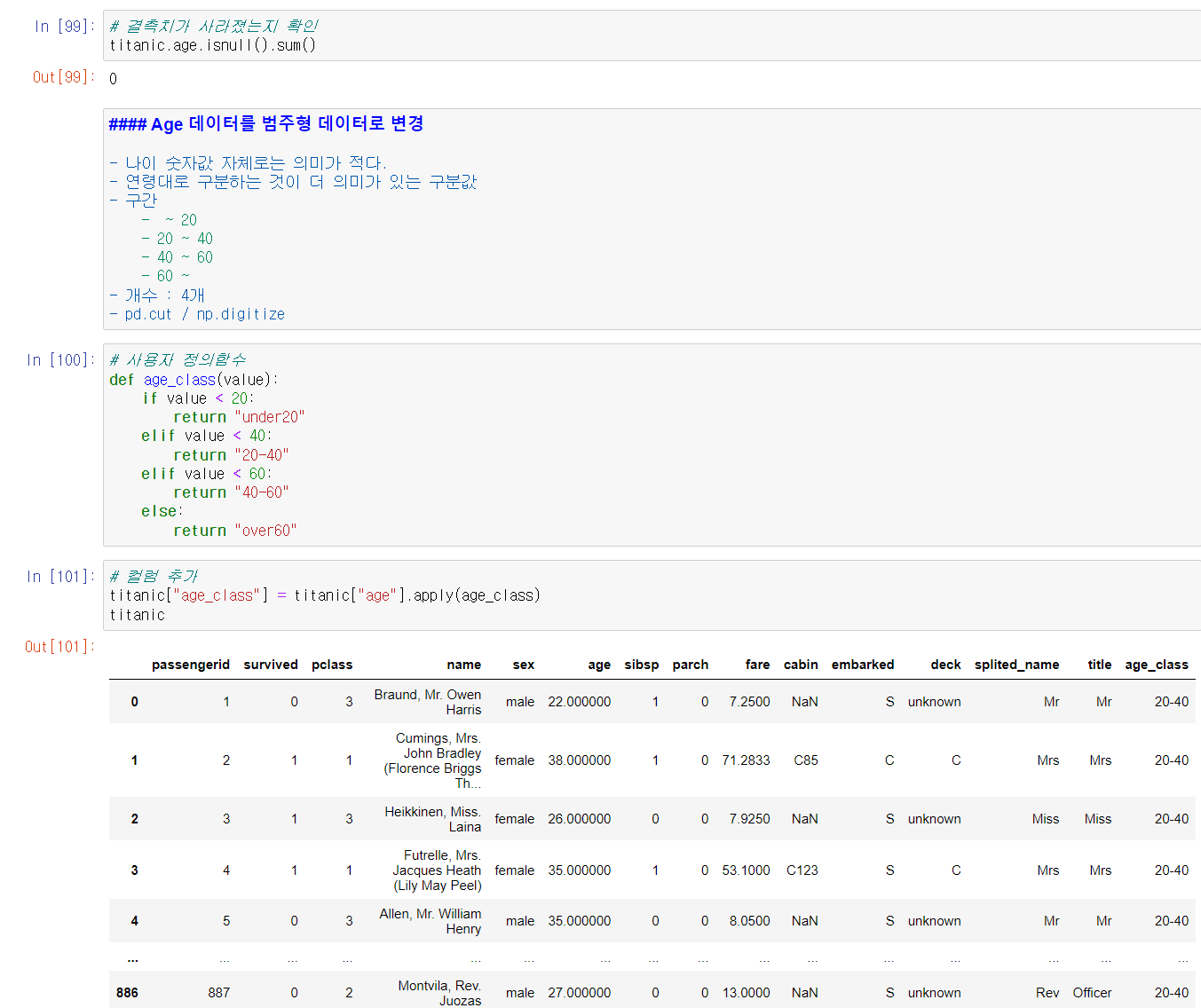
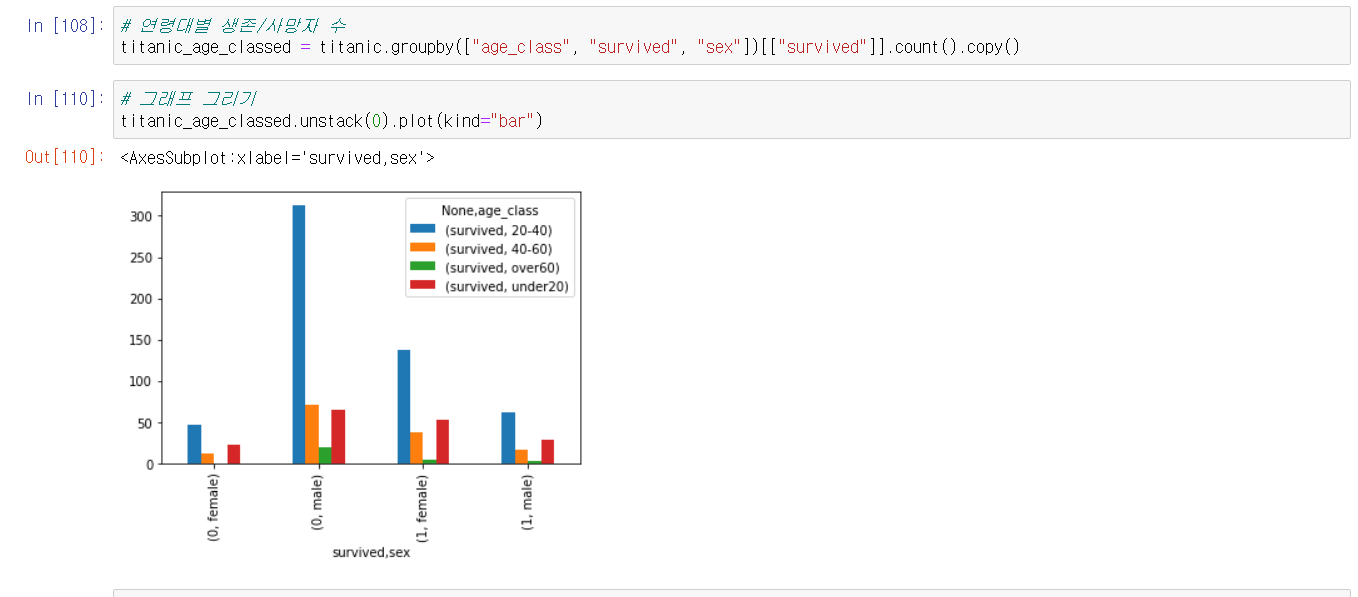
마지막으로 간단한 데이터 시각화를 진행했는데, 나이대/성별 별 생존 여부와 탑승 등급별 생존 여부에 대한 막대 그래프를 그렸다.

이렇게 빅데이터 부트캠프의 첫 번째 파트라고 할 수 있는 파이썬 기초 강의 부분이 종료되었다. 다음주부터는 머신러닝에 대해 공부할 예정이고, 당연하게도 파이썬 기초에서 배운 부분들, 특히 데이터 전처리 부분이 자주 활용될 것이기 때문에 복습을 통해 학습하는 것이 좋겠다. 머신러닝 파트를 배우기 전 주말 동안, Titanic 데이터 말고 다른 데이터들, 예를 들면 보스턴 집값 데이터 등을 통해 배운 내용을 실습하면서 복습하도록 해야겠다.
'Python' 카테고리의 다른 글
| Day 21 - 머신러닝 2 > 로지스틱 회귀 (0) | 2022.11.08 |
|---|---|
| Day 20 - 머신러닝 1 > 선형회귀 (0) | 2022.11.07 |
| Day 18 - 데이터 전처리 (0) | 2022.11.01 |
| Day 16/17 - 미니프로젝트(넷플릭스 인기컨텐츠의 장르와 계절간의 관계) (0) | 2022.10.31 |
| Day 16 - api 크롤링 (0) | 2022.10.31 |