2022. 11. 7. 17:35ㆍPython
이번 글에서는 머신러닝 중 선형회귀에 대해 공부했다.
우선 머신러닝에 대해 설명할 필요가 있는데, 주로 머신러닝과 함께 헷갈리는 개념들인 인공지능, 딥러닝의 개념을 함께 정리해보면 다음과 같다.
- 인공지능: 인간의 뇌를 모방한 프로그램. 세 개념 중 최상위 개념이다.
- 머신러닝: 데이터를 기반으로 학습하여 무언가를 예측하거나, 데이터 자체의 특성을 찾아내는 것.
- 딥러닝: 머신러닝 알고리즘의 한 종류로 인공 신경망에서 진화한 형태. 주로 이미지/비디오/자연어 분석에 쓰임. 세 개념 중 최하위 개념이다.
머신러닝은 기본적으로 데이터수집 > 데이터 전처리 > 모델학습 > 모델평가 > 모델배포의 프로세스를 통해 이루어진다. 위 프로세스를 반복하는 것을 MLOps라고 한다.
이 중 머신러닝 방법 중 하나인 선형회귀에 대해 간단히 공부하고 실습해보았다. 선형회귀란, 연속된 변수를 예측하는 최적의 직선을 찾는 알고리즘 방법론으로, 여러가지 데이터를 활용하여 목표 변수를 예측하는 것이 목적이다.
kaggle의 insurance 데이터를 활용하여 Google colab에서 선형회귀 실습을 진행했다.
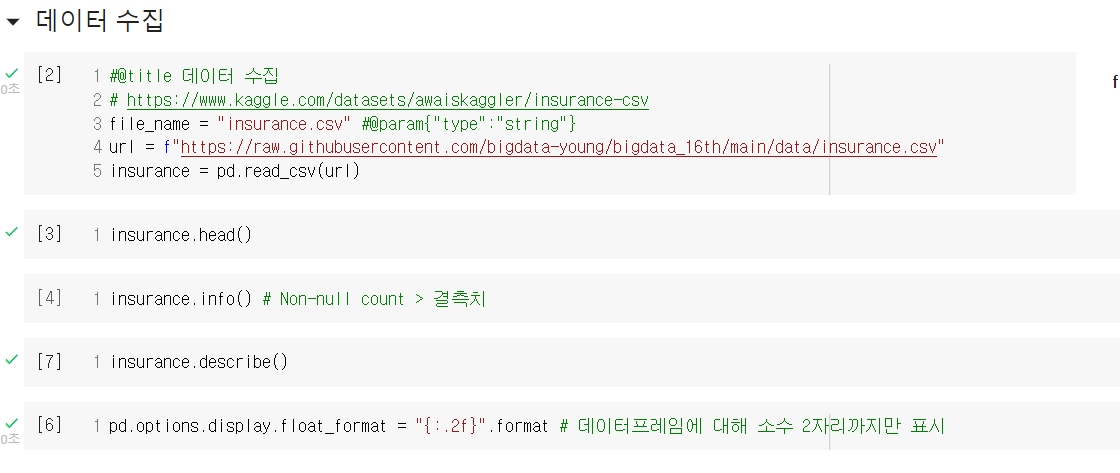
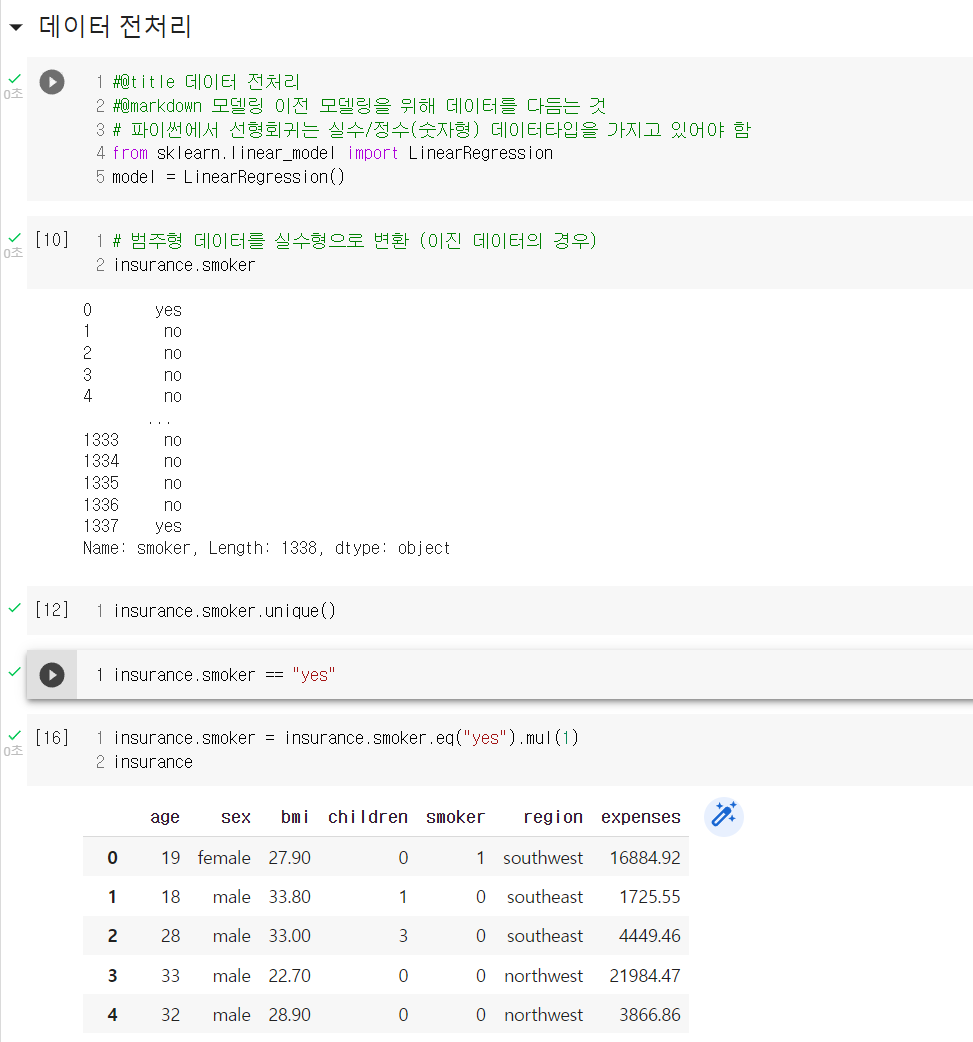
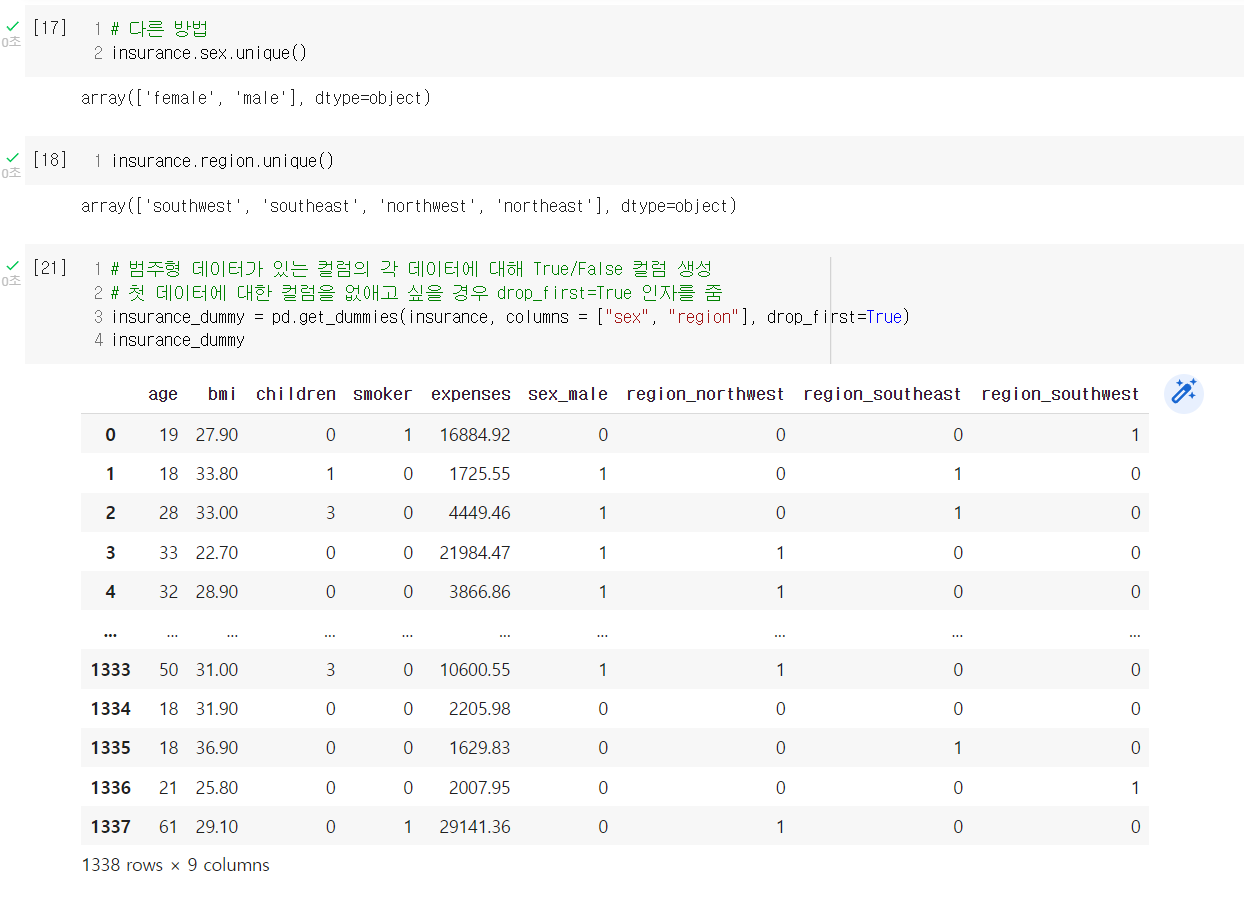
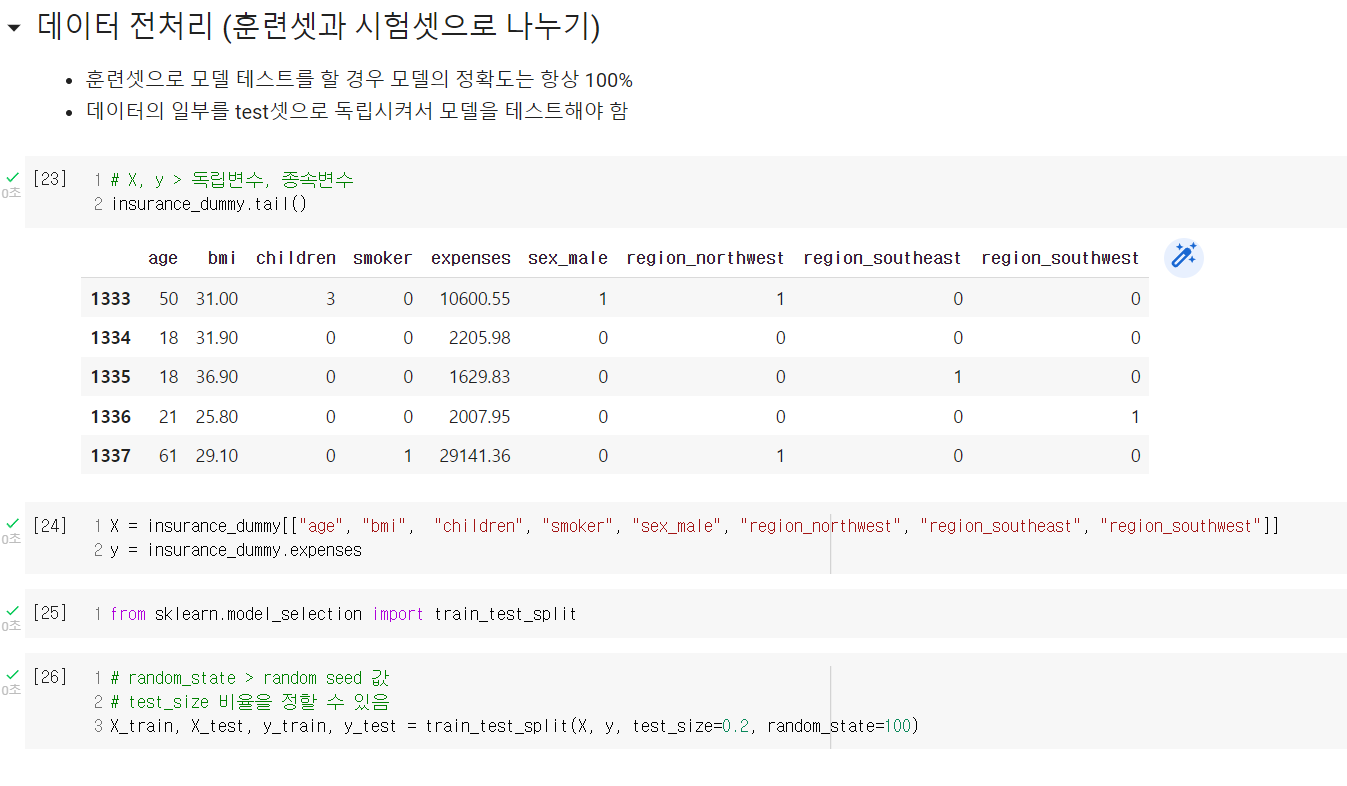

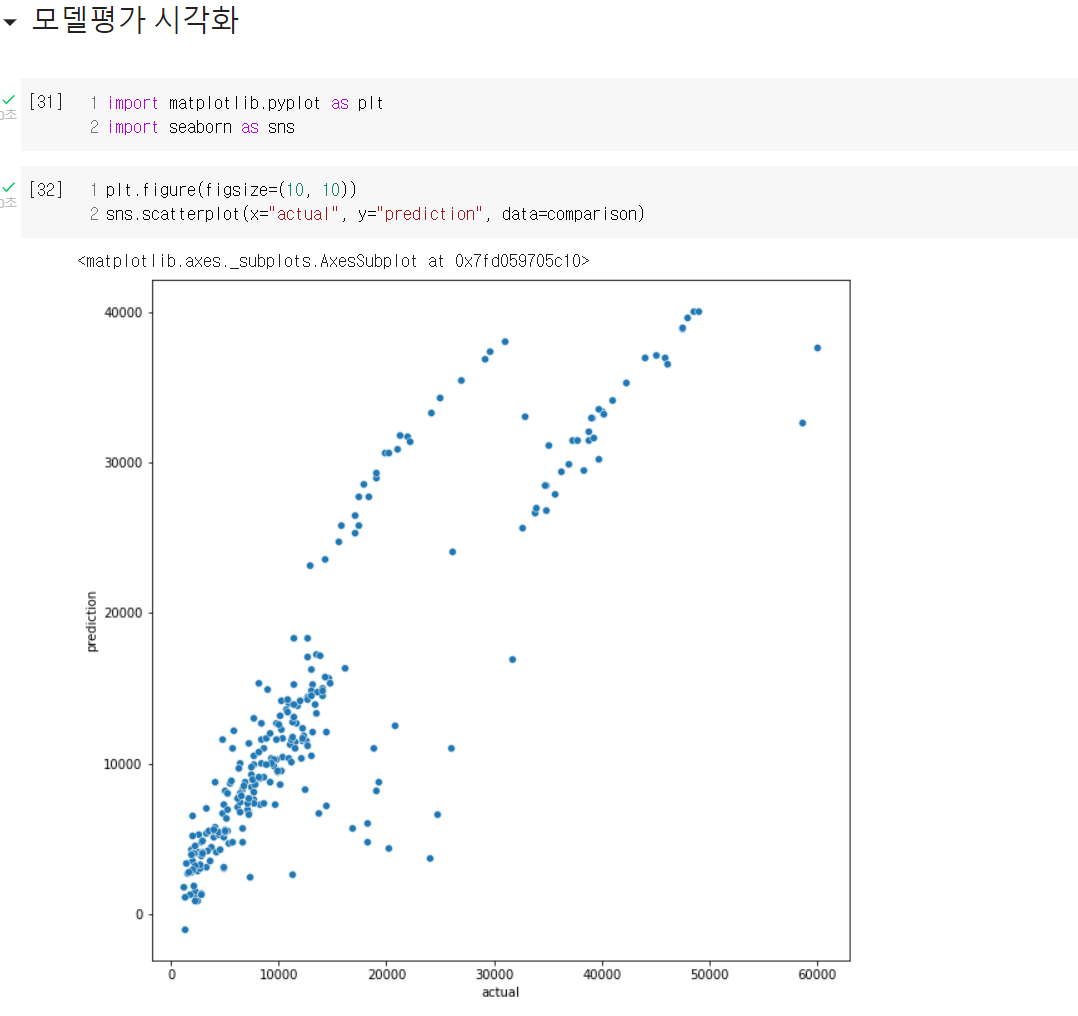
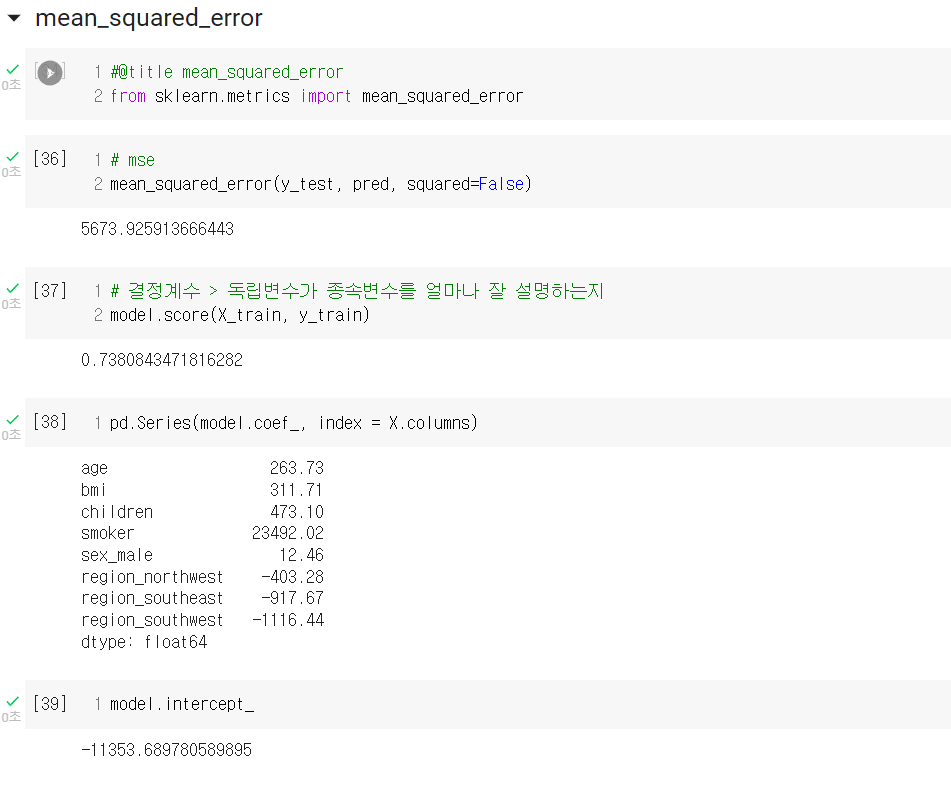
모델 배포는 GitHub, Streamlib, Notion 등의 개발자를 위한 사이트를 이용하는데, 이들 사이트를 이용하는 방법은 다른 글에서 좀 더 자세히 다룰 것이다. 오늘 강사님이 간단히 가르쳐주시긴 했는데, 내가 스스로 해보면서 좀 더 이해가 필요하기 때문이다.
'Python' 카테고리의 다른 글
| Day 22 - 머신러닝 3 > KNN(K - Nearest Neighbors) (0) | 2022.11.09 |
|---|---|
| Day 21 - 머신러닝 2 > 로지스틱 회귀 (0) | 2022.11.08 |
| Day 19 - Titanic 데이터 실습 (0) | 2022.11.02 |
| Day 18 - 데이터 전처리 (0) | 2022.11.01 |
| Day 16/17 - 미니프로젝트(넷플릭스 인기컨텐츠의 장르와 계절간의 관계) (0) | 2022.10.31 |