2022. 11. 14. 16:40ㆍPython
이번 글에서는 머신러닝 알고리즘 중 랜덤 포레스트에 대해 다룰 것이다. 이제는 본격적으로 사람이 해석하거나 설명하기 어려운 알고리즘의 단계까지 도달했다.
랜덤 포레스트는 기본적으로 결정 트리를 확장한 것이라고 이해하는게 좋을 것 같다. 랜덤으로 생성된 무수하게 많은 트리를 앙상블 기법*을 통해 예측하는 알고리즘으로, 결정 트리의 오버피팅 문제를 해결할 수 있다. 트리모델이기 때문에 아웃라이어에 영향을 받지 않으며 종속변수의 데이터 타입에 관계 없이 사용할 수 있고, 데이터의 선형/비선형 관계를 구별하지 않는다는 장점이 있다. 다만, 속도가 느리고 모델 해석이 어렵다는 단점이 있다. 이 모델 해석의 경우에는 앙상블 기법을 사용하는 모델의 경우에는 공통적으로 적용되는 단점이라고 할 수 있다.
*앙상블 기법: 여러 모델을 활용하여, 각 모델의 예측값을 투표 및 평균 등으로 통합하여 더 정확한 예측을 추구하는 기법
Kaggle의 중고차 가격 데이터셋을 통해 랜덤 포레스트를 실습해보았다.

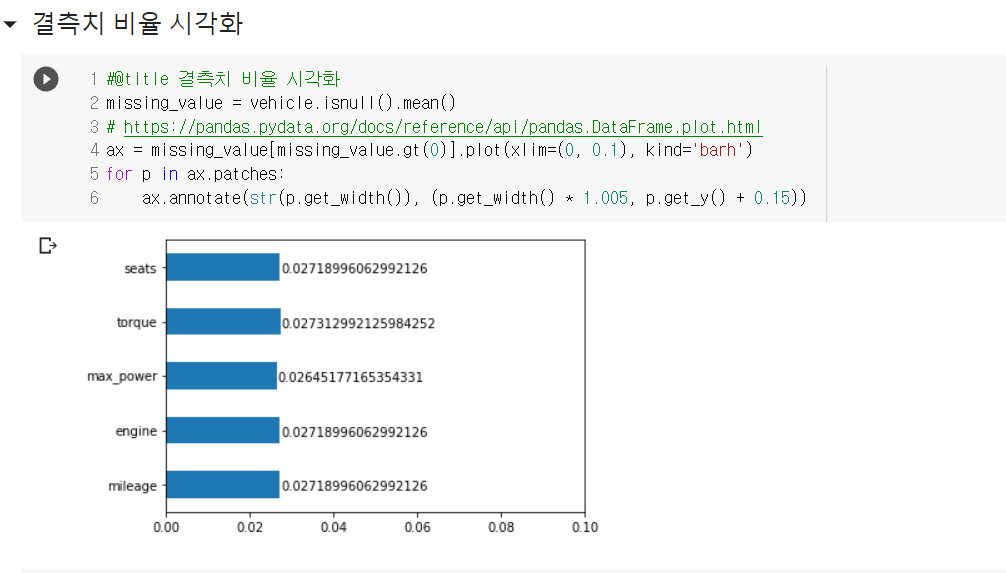


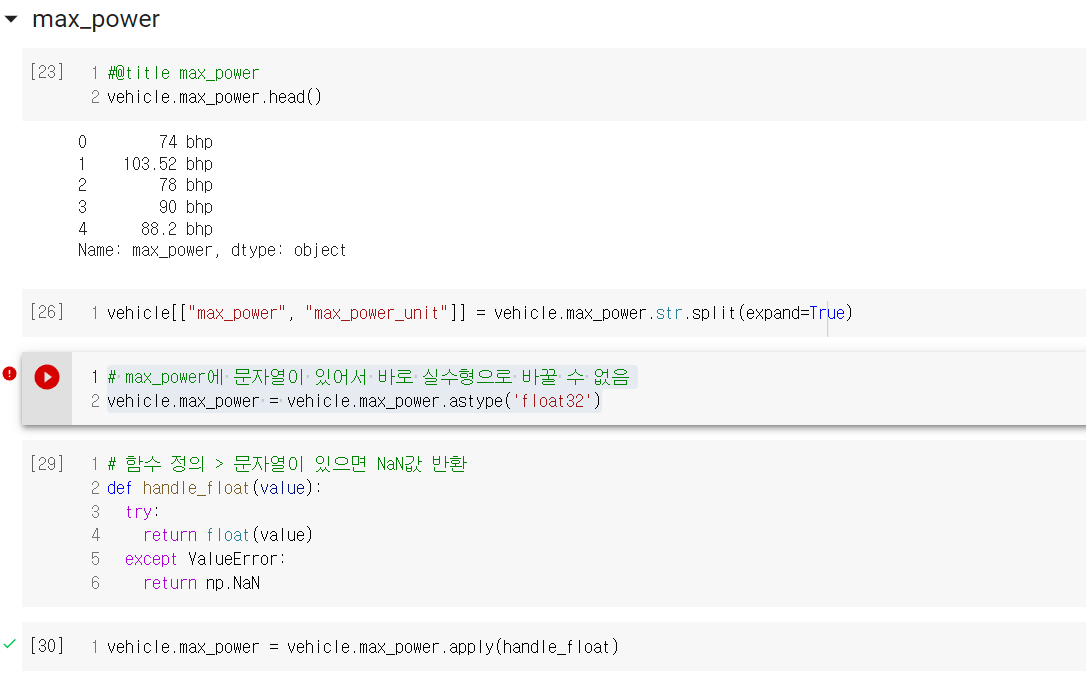

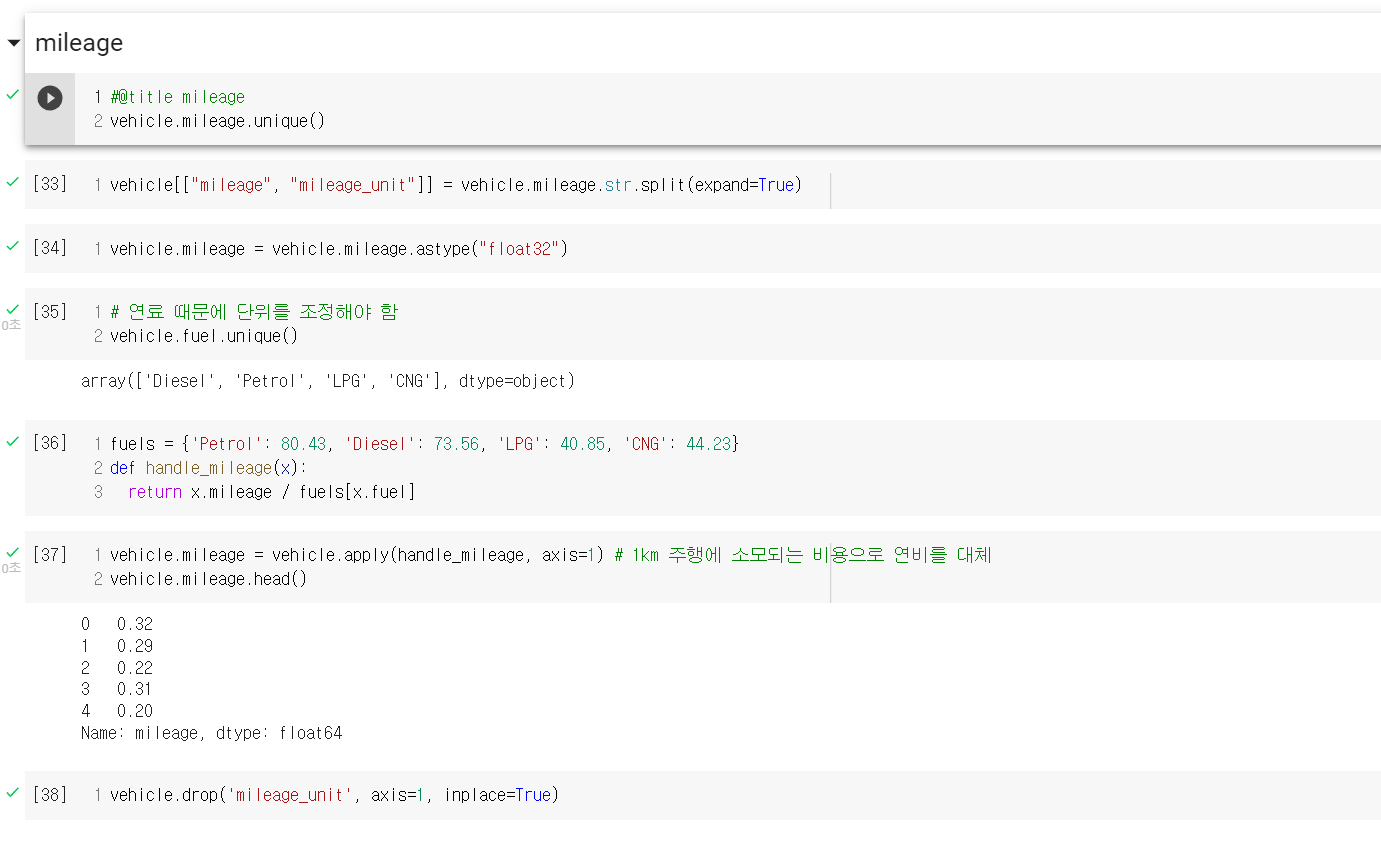
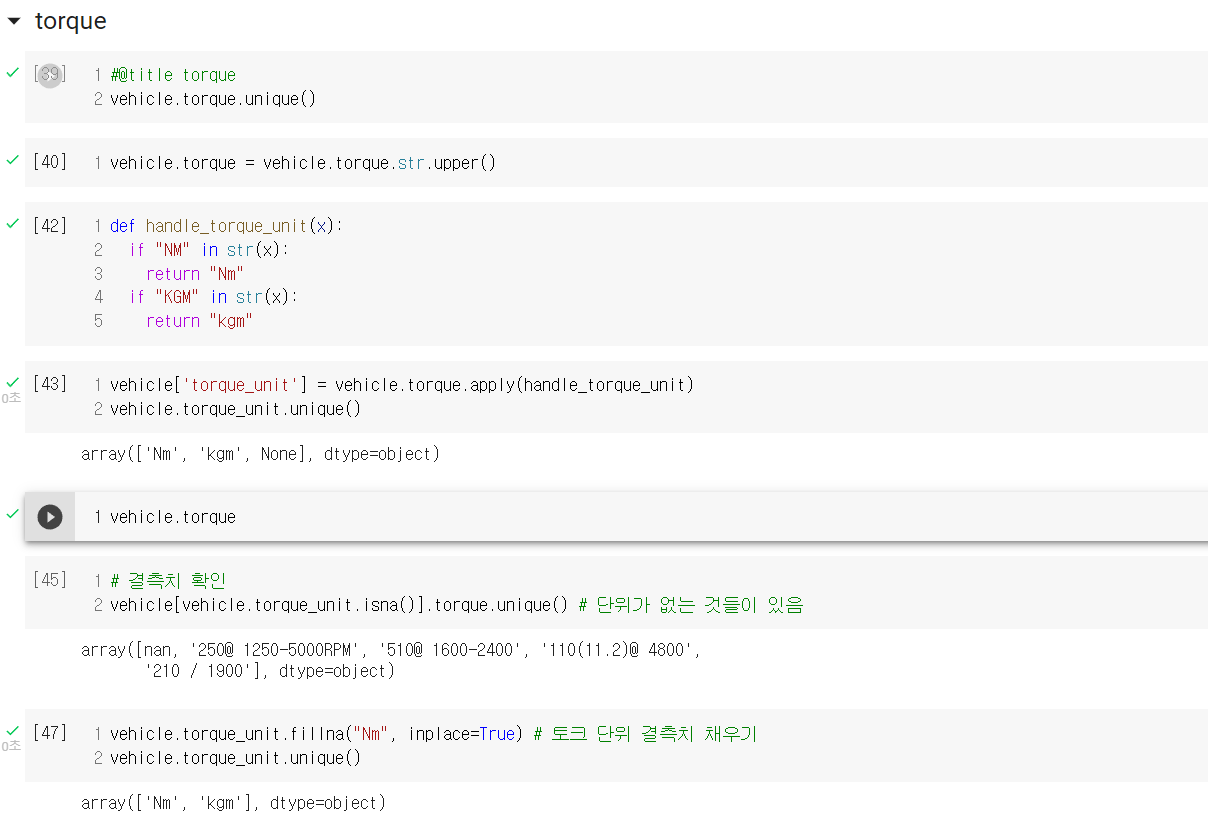


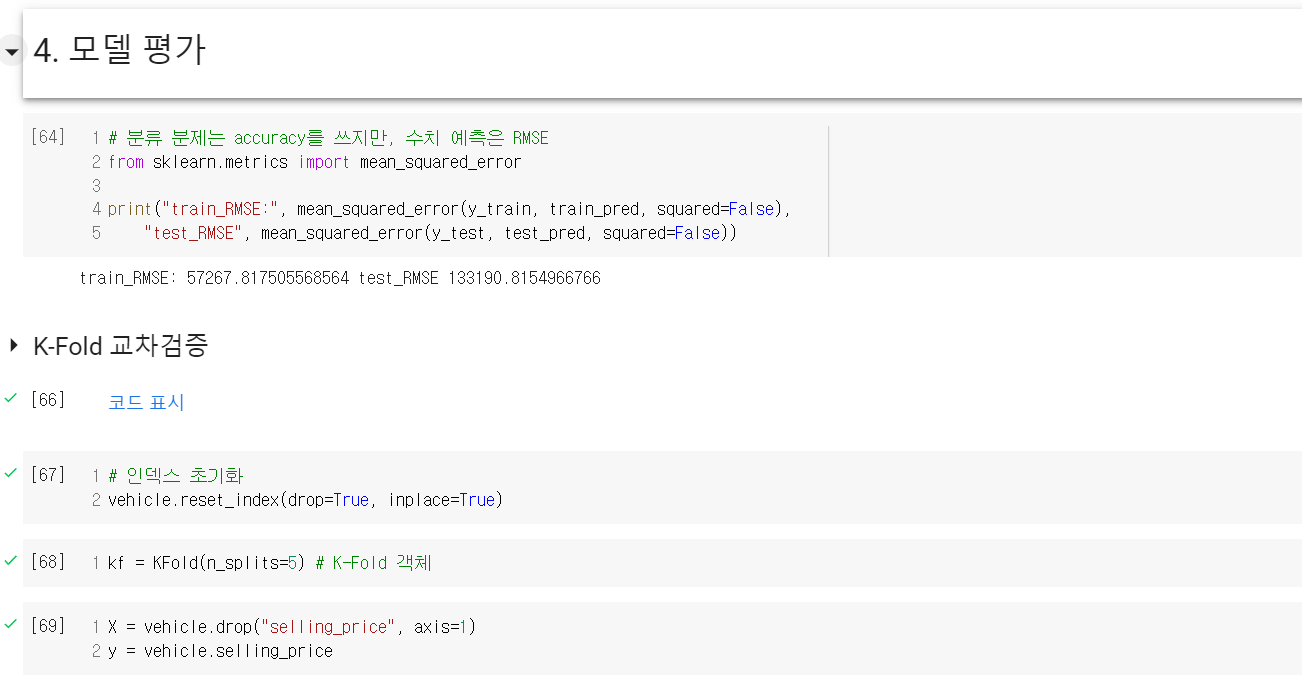
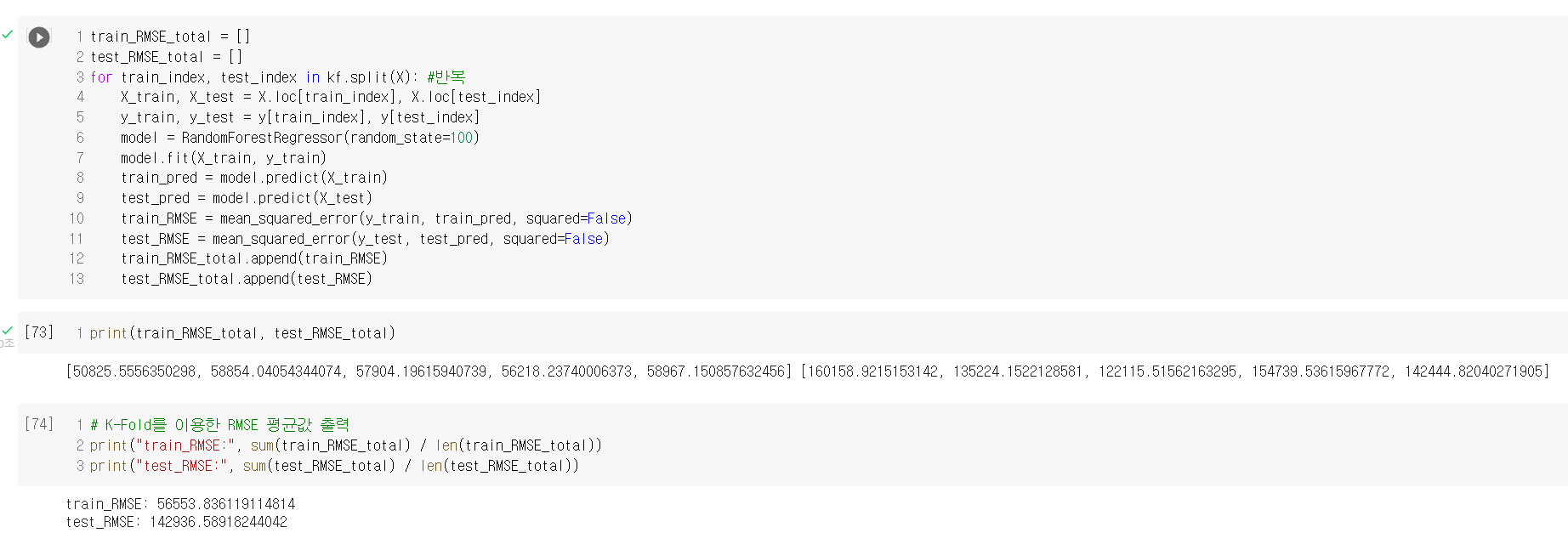
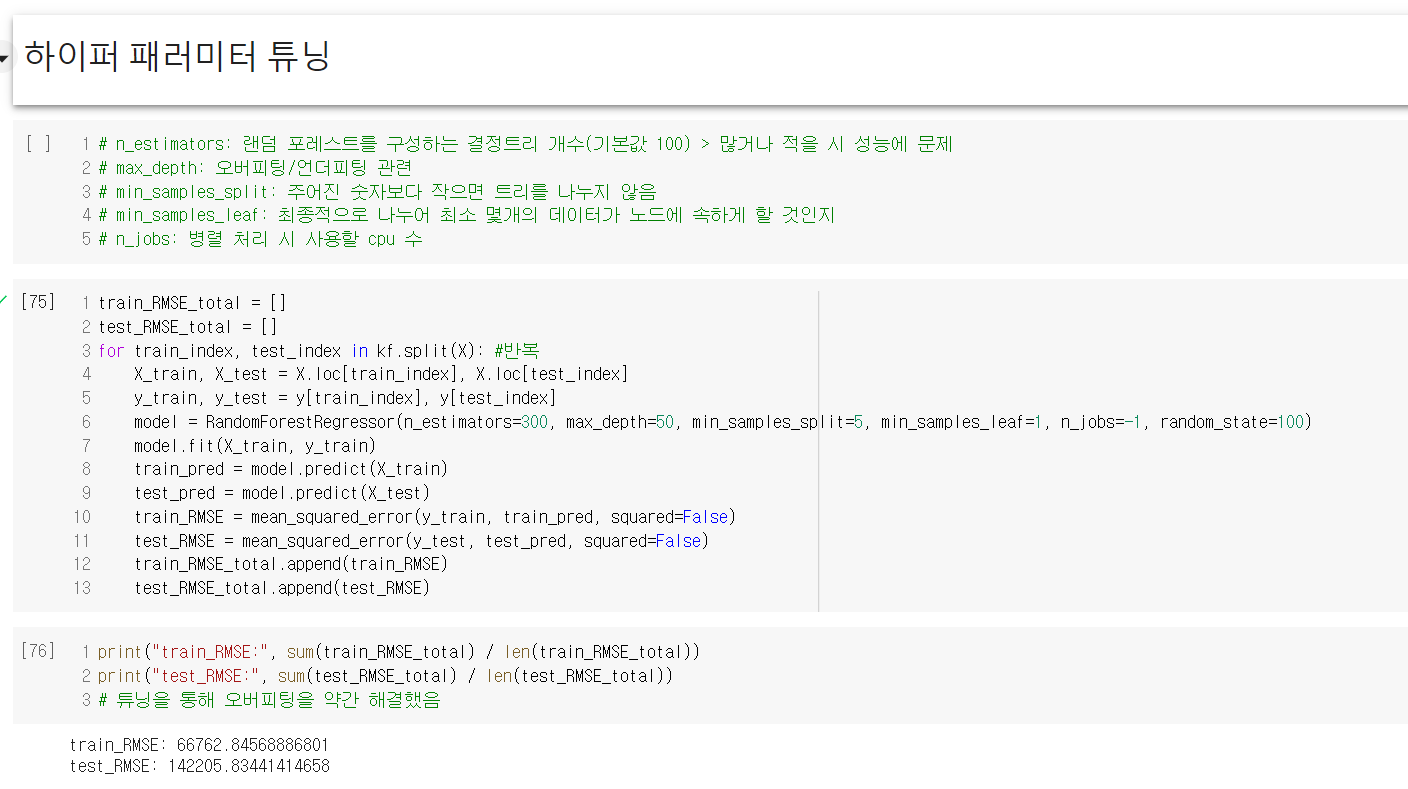
랜덤 포레스트의 경우 기초적인 트리 모델에 비해 성능은 확실히 뛰어나나, 그 알고리즘이 매우 복잡하기 때문에 원리까지는 인간이 이해해도 모델을 학습한 결과가 왜 이렇게 나왔는지는 이해할 수 없는 경우가 대다수이다. 이렇게 설명력이 낮은 알고리즘들이 이후에는 계속 등장할텐데, 나만 이해 못하는 것은 아닐테니 너무 어렵다고는 생각하지 말아야겠다. 그리고 머신러닝 관련 게시글에서 항상 이 말을 덧붙이는 것 같은데, 역시 전처리 과정이 제일 까다롭고 지난하고 중요하다고 생각이 든다.
'Python' 카테고리의 다른 글
| Day 26 - 머신러닝 8 > LightGBM (0) | 2022.11.15 |
|---|---|
| Day 26 - 머신러닝 7 > XGBoost (0) | 2022.11.15 |
| Day 23/24 - 머신러닝 5 > 결정 트리 (Decision Tree) (0) | 2022.11.12 |
| Day 22/23 - 머신러닝 4 > 나이브 베이즈 (Naive Bayes) (0) | 2022.11.09 |
| Day 22 - 머신러닝 3 > KNN(K - Nearest Neighbors) (2) (0) | 2022.11.09 |