2022. 10. 24. 22:01ㆍPython
이번 글에서는 Pandas 라이브러리로 만든 DataFrame의 계층색인, 정렬, 병합, 집계, 통계에 대해 다룰 것이다.
계층색인이란, 인덱스에 계층이 있는 것을 의미한다. 이를 DataFrame에서 예시로 들면, "서울"이라는 상위계층 컬럼에 "2021년"과 "2022년"의 하위계층 컬럼들이 속하는 것이 된다.

주의해야 할 점을 실습 캡쳐를 통해 정리해보면,




위와 같은 것들이 주의해야 할 점이 되겠다.
다음 정리할 것은 DataFrame과 Series의 정렬이다. 정렬의 경우 실제 데이터 전처리에서 많이 쓰이기 때문에 제대로 공부해서 이해하는 것이 중요하다. 특히, 일반적인 sort()를 쓰는게 아니라 인덱스와 데이터를 각각 sort_index()와 sort_values()로 따로 정렬하는 메서드가 있다는 것을 기억해두자.

위와 마찬가지로 헷갈리는 부분들을 실습 캡쳐를 통해 확인해보면,

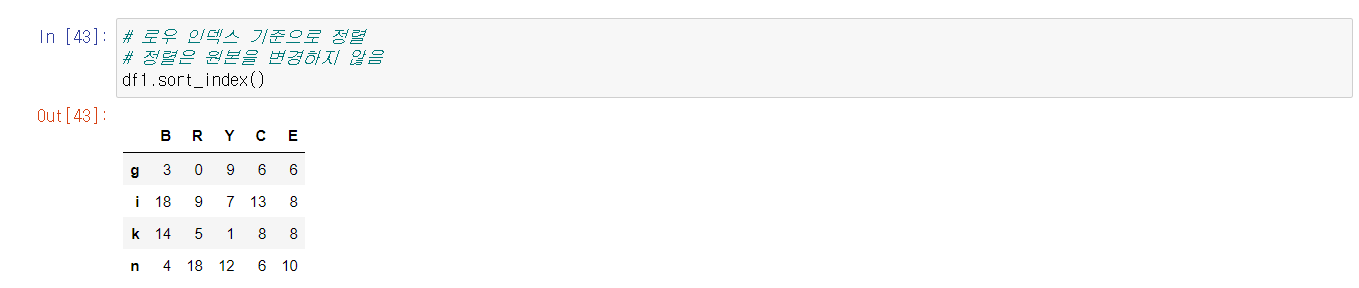
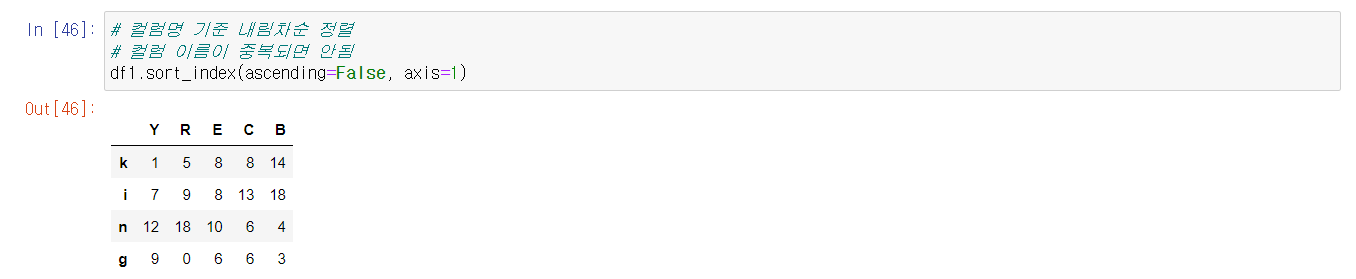

위와 같은 사항들은 반드시 외우도록 하자.
다음은 연습문제와 그 풀이이다.
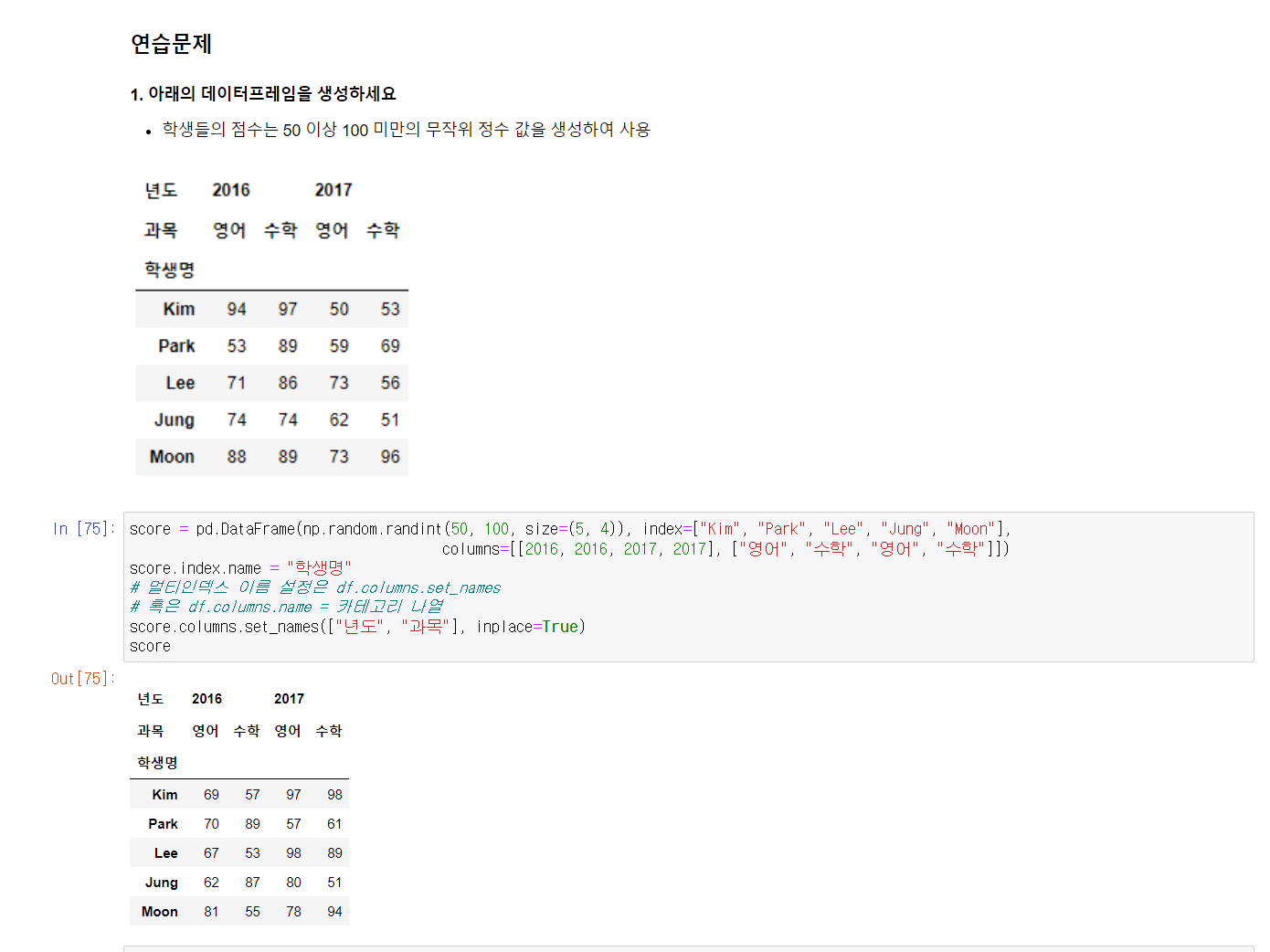
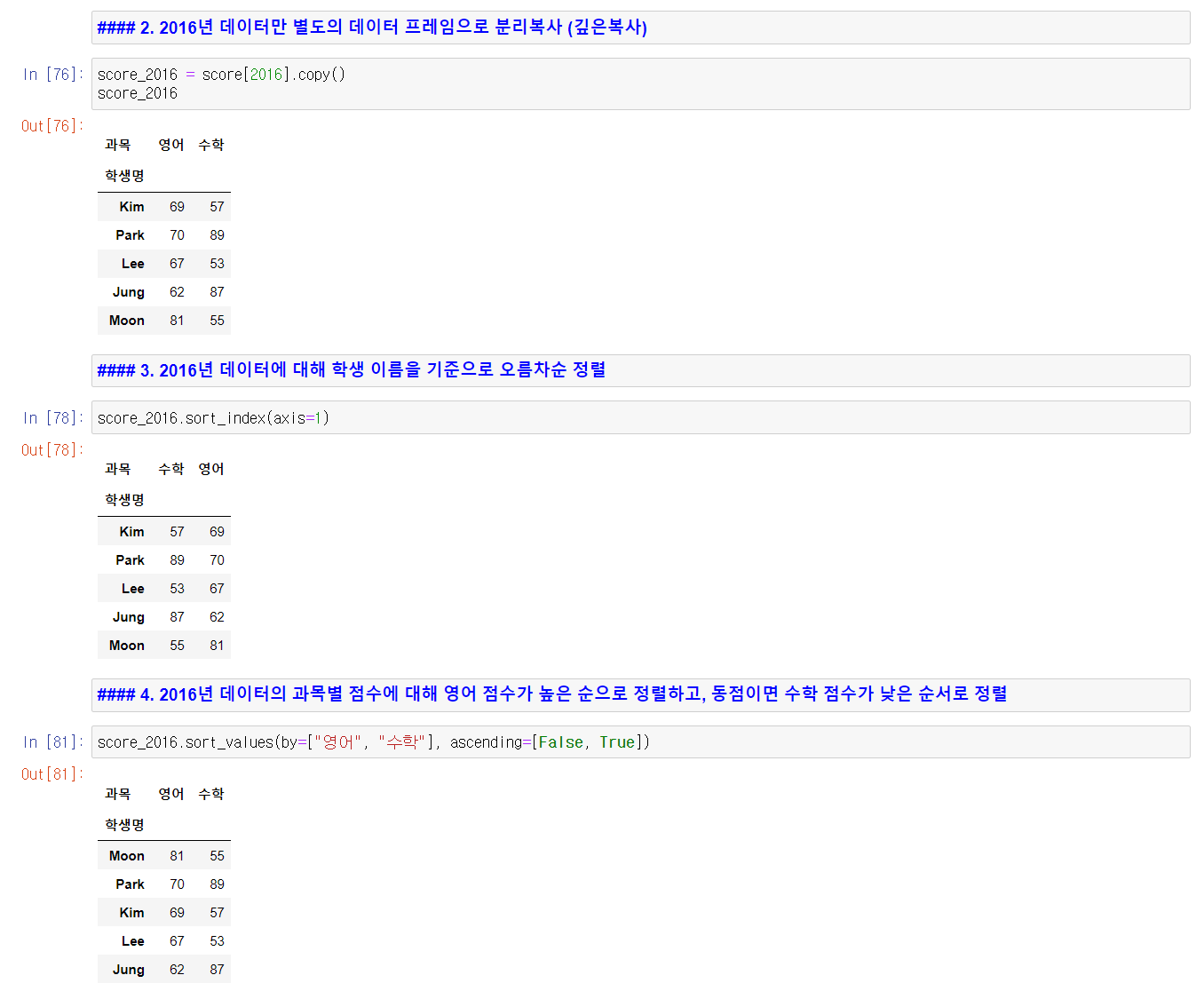
다음에 정리할 내용은 데이터 합치기이다. DataFrame에서 데이터를 합치는 것에는 두 개의 DataFrame을 특정 컬럼 기준으로 합치는 merge와, 두 개의 DataFrame을 행과 열 기준으로 연결하는 concat이 있다.


merge의 경우 기본적인 동작이 교집합인 데이터만 합치는 것으로 하며, 합집합과 각 여집합을 합치는 방법이 있다는 것과 그 방법들, 그리고 그 경우에 교집합이 아닌 경우 NaN값이 출력된다는 사실을 공부하자. 또한 on인자의 경우 공통된 이름을 가진 컬럼이 두 개 이상이거나, 두개의 서로 다른 컬럼이 같은 데이터를 가리킬 때 사용한다.
concat의 경우 두 Series를 연결해서 DataFrame을 생성할 수 있고, 행방향 및 열방향 모두로 합칠 수 있다는 것을 알아두자.
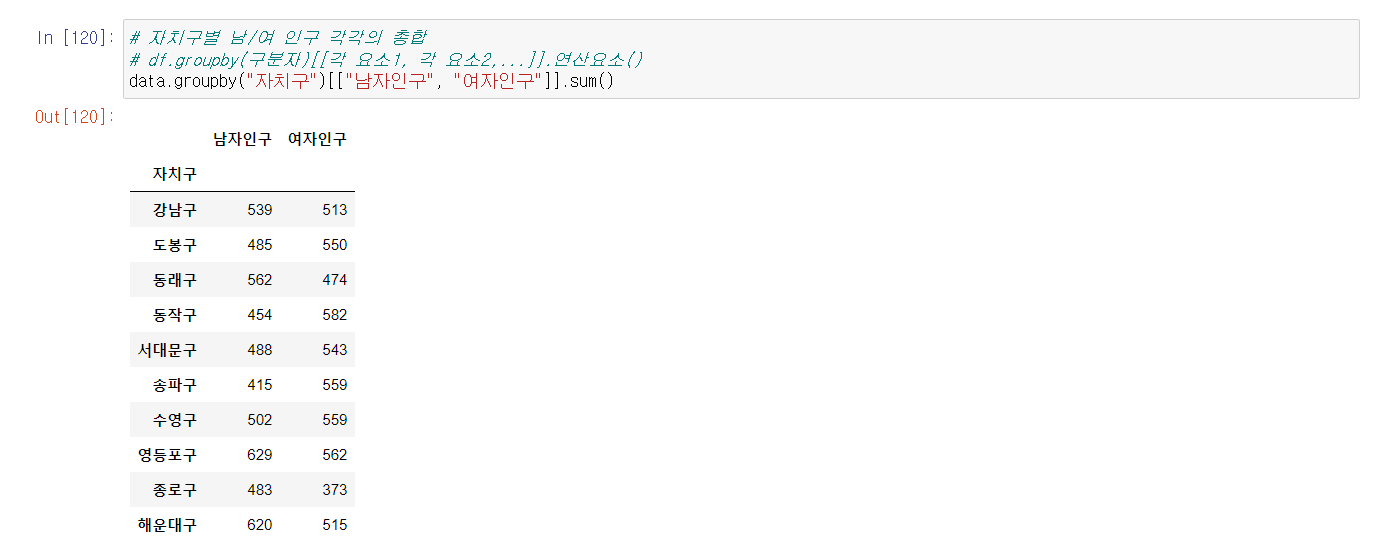
마지막으로 정리할 내용은 데이터 집계이다. 데이터 집계는 사용자가 특정 DataFrame에서 알고 싶은 데이터를 정리해서 보여주는 역할을 수행한다.

마찬가지로, 위와 같이 주의할 사항을 정리하면,
마지막으로 정리할 내용은 DataFrame의 통계 메서드에 관한 것이다. DataFrame에 대해 기초적인 통계작업 수행이 가능하다.

위 메서드들에 익숙해지도록 하자.
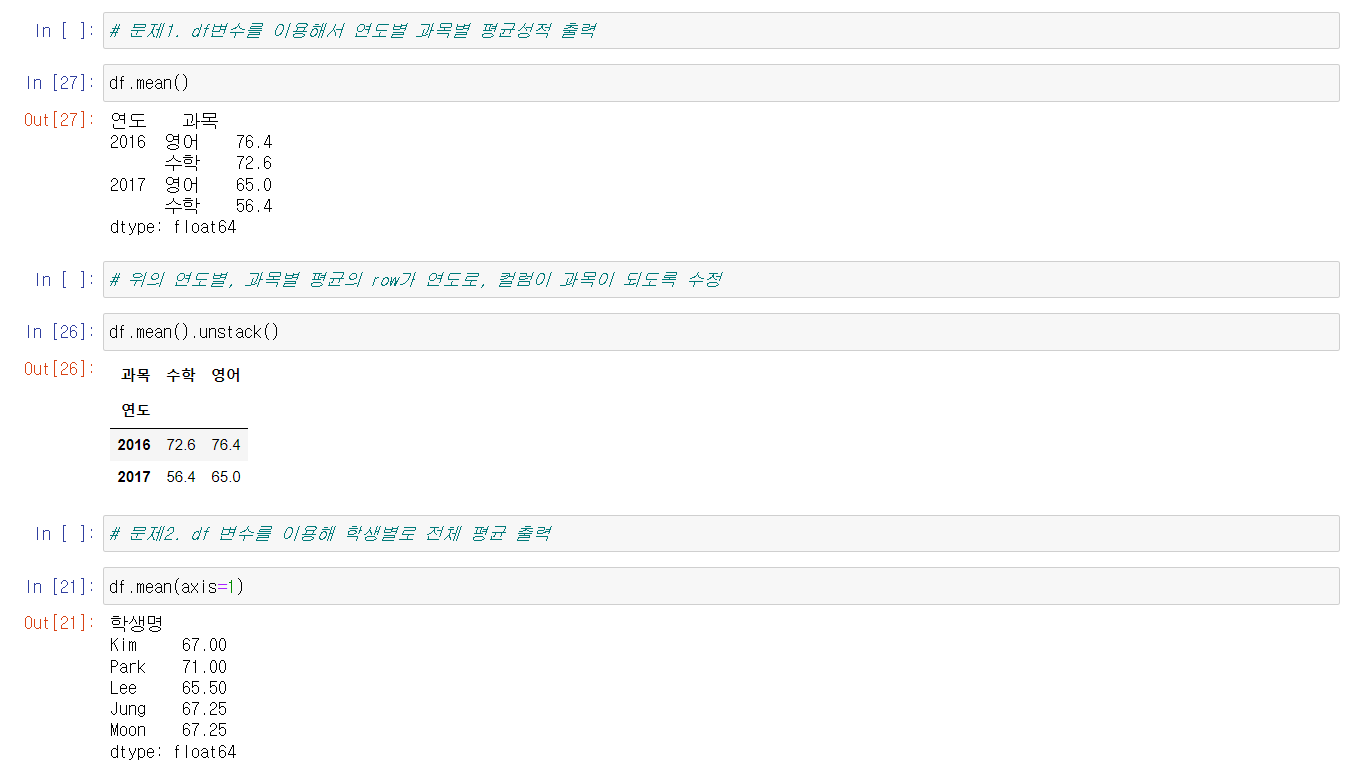
아래는 연습문제 풀이 캡쳐이다.
'Python' 카테고리의 다른 글
| Day 15 - 데이터 시각화 (0) | 2022.10.25 |
|---|---|
| Day 15 - 데이터 전처리 및 기초 데이터 통계 실습 (0) | 2022.10.25 |
| Day 13/14 - Pandas (2) (0) | 2022.10.21 |
| Day 12/13 - Pandas (0) | 2022.10.20 |
| Day 12 - Numpy (6) (0) | 2022.10.20 |