2022. 10. 21. 18:31ㆍPython
이번 글에서는 Series와 더불어 Pandas의 대표적인 자료형인 DataFrame에 대해 다룰 것이다. DataFrame은 엑셀이나 csv 자료형과 유사해서 이 둘을 생각하면 이해가 빠를 것이다.
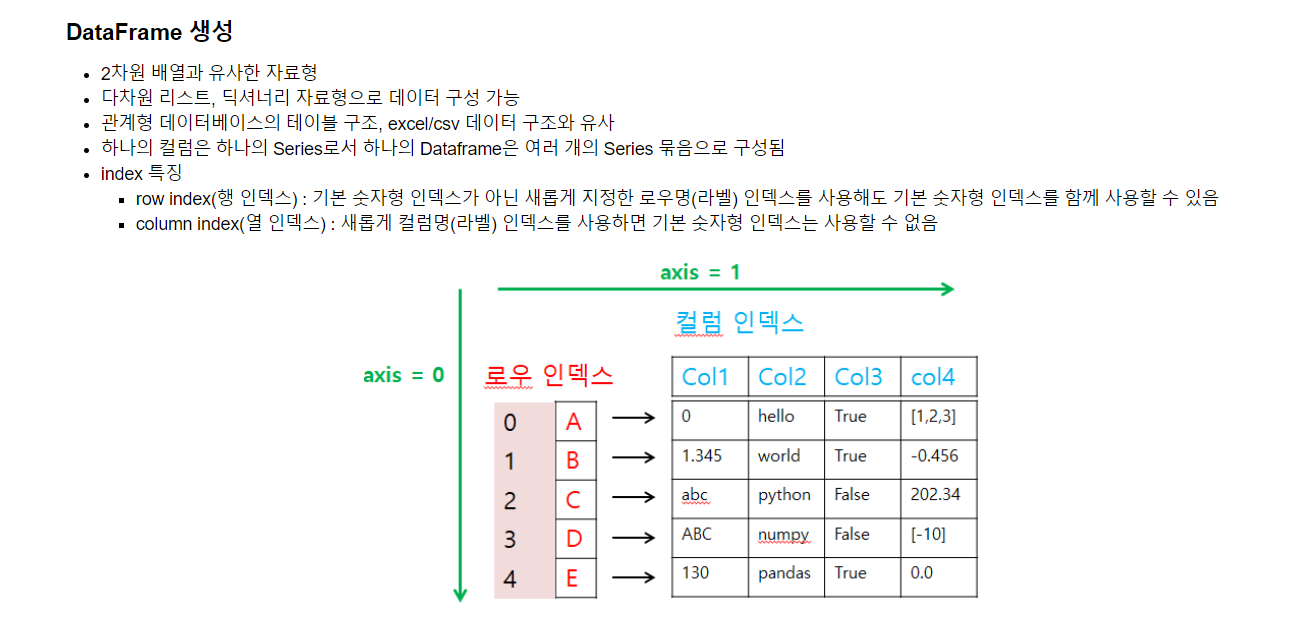
다음은 DataFrame 생성 실습 중 헷갈리기 쉽거나 외워야 하는 부분만 캡쳐한 것이다.
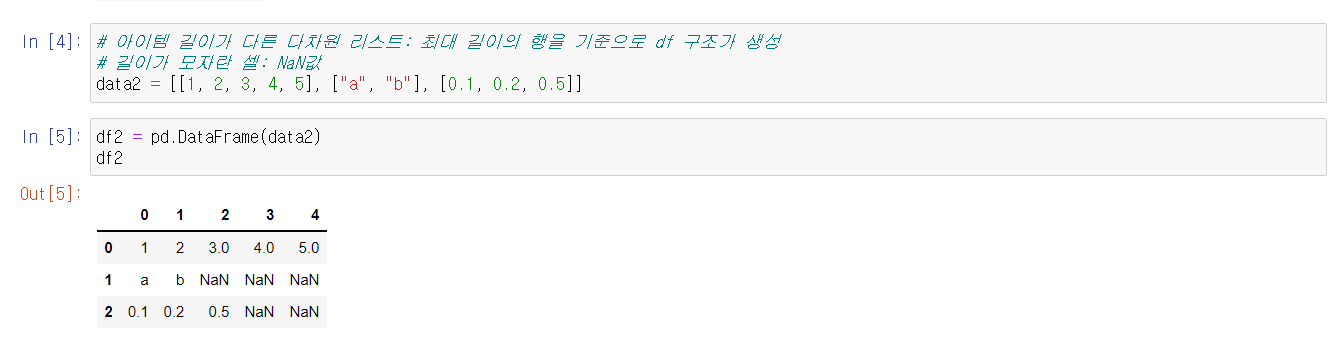
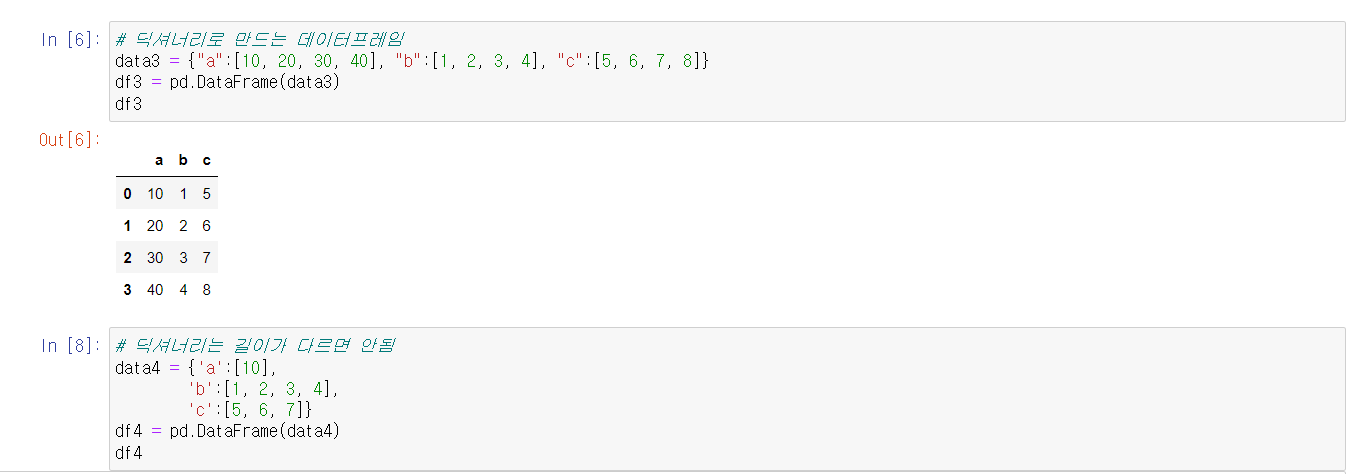
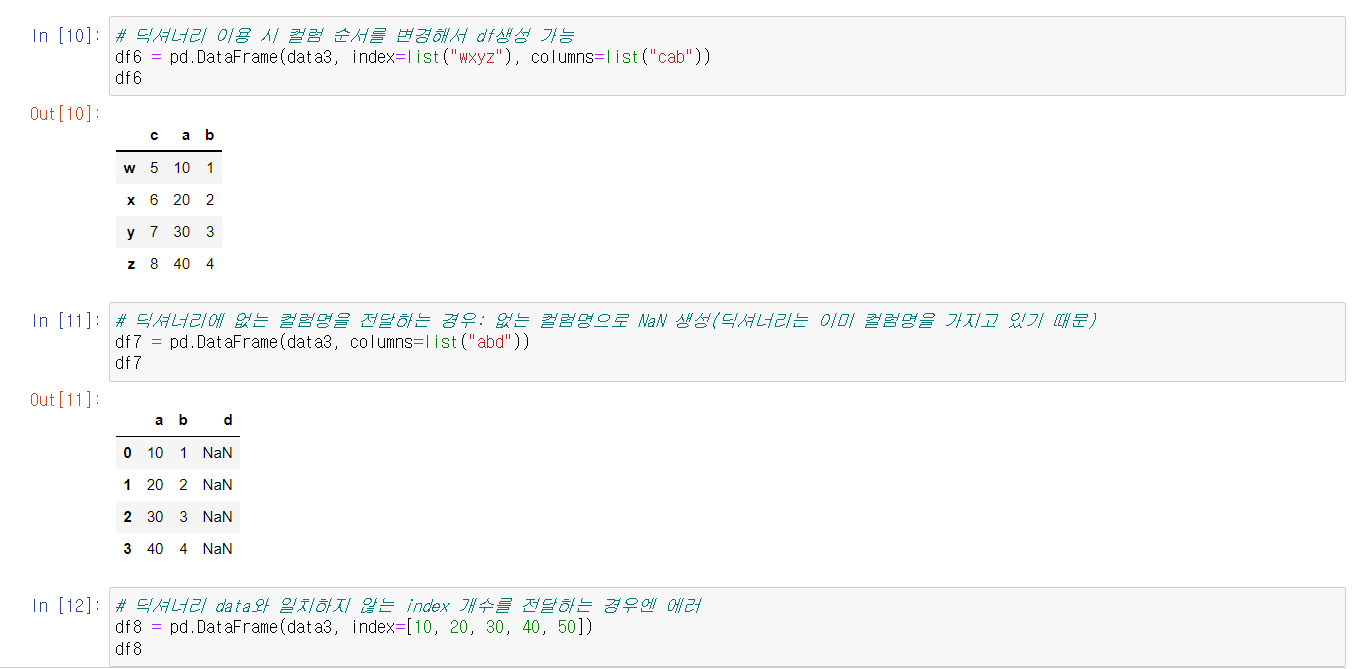
DataFrame의 속성을 알아보는데는 여러 메서드가 존재한다. 다만, Series와 마찬가지로 속성을 알아보는 함수에는 소괄호를 붙이지 않는다.

한 편 실습 중 위 사진의 메서드에 없는 것도 함께 실습했다.
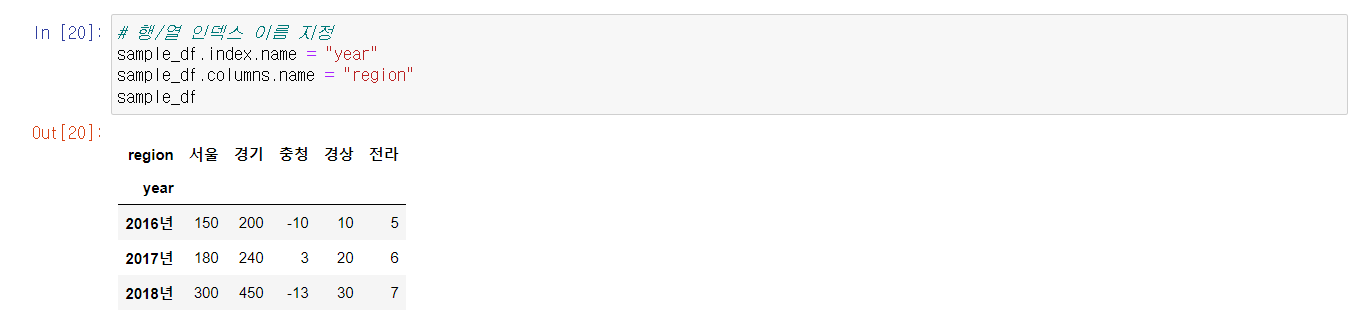
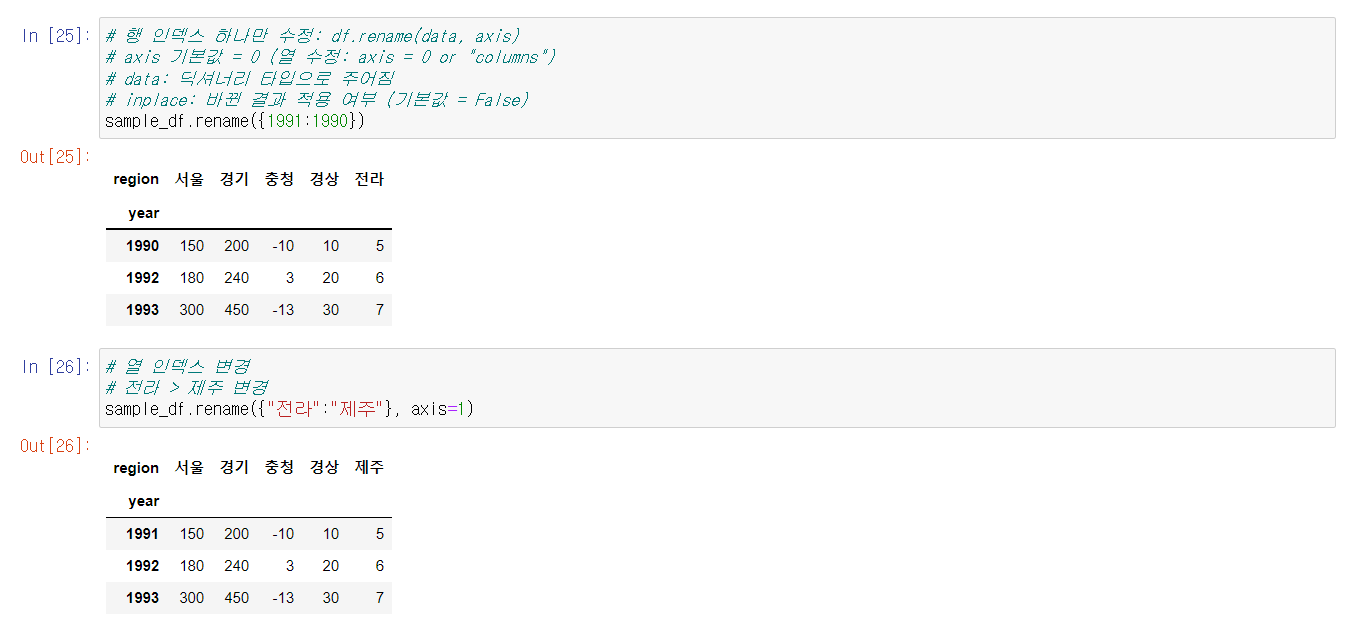
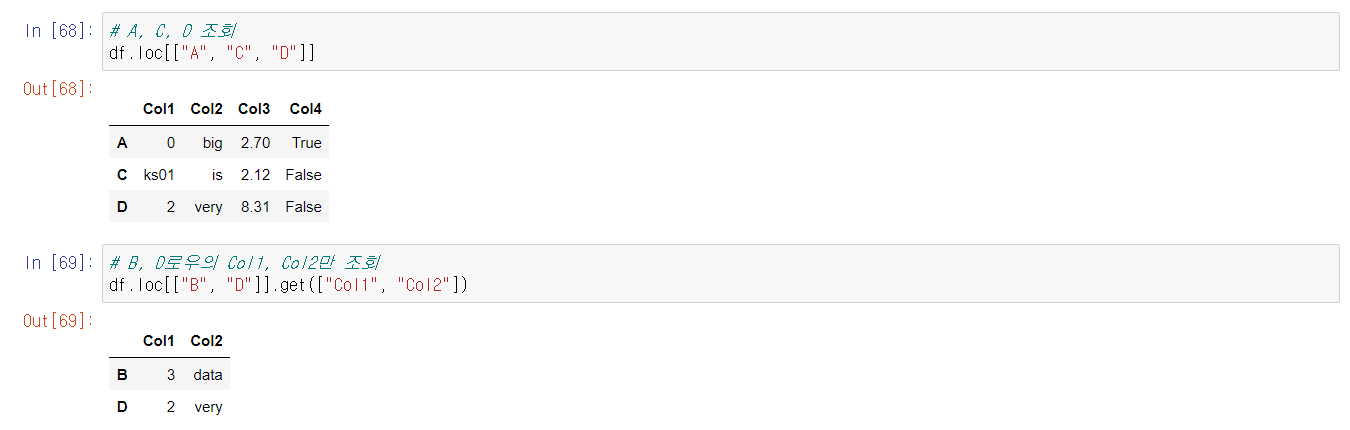
또한 대부분의 데이터형들과 마찬가지로, DataFrame 역시 인덱싱과 슬라이싱이 가능하다. 방식은 Series 인덱싱 및 슬라이싱과 비슷하지만, DataFrame 인덱싱은 더 다양한 메서드를 갖추고 있다.


인덱싱에서 row를 조회할 때 .iloc과 .loc의 용도가 다르다는 점, 그리고 column 슬라이싱 시에 다른 것과 다르게 마지막 인덱스를 포함한다는 점을 기억하자.
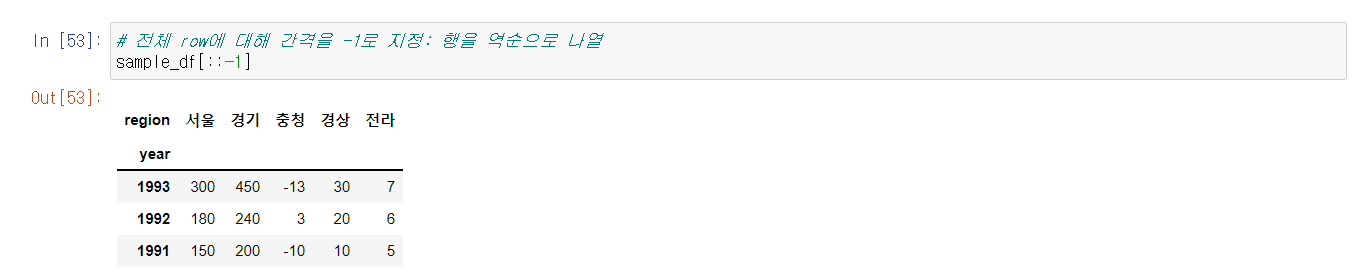
마찬가지로 실습에서 중요한 부분만 캡쳐했다.



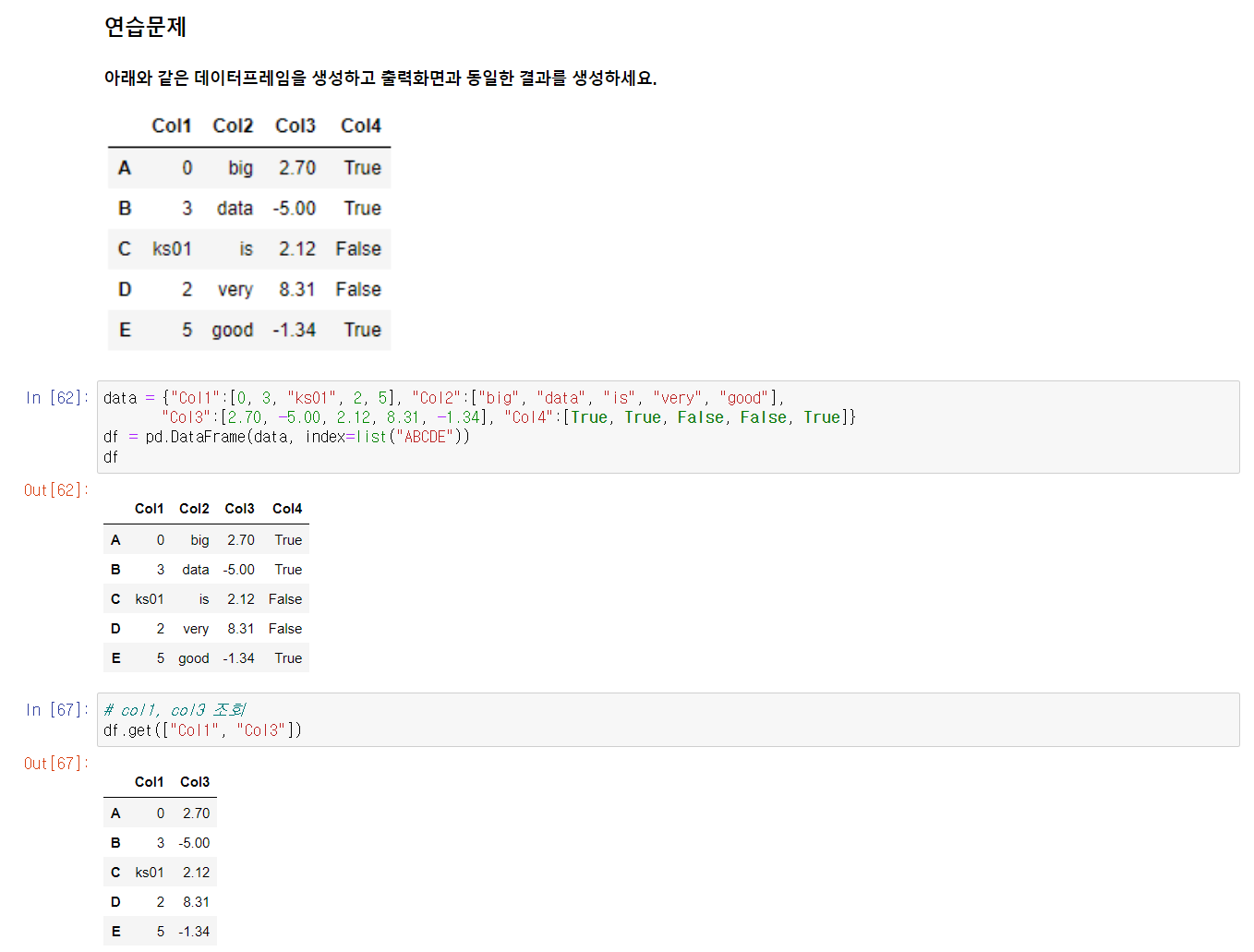
DataFrame 생성과 인덱싱, 슬라이싱에 관한 연습문제를 풀었다.
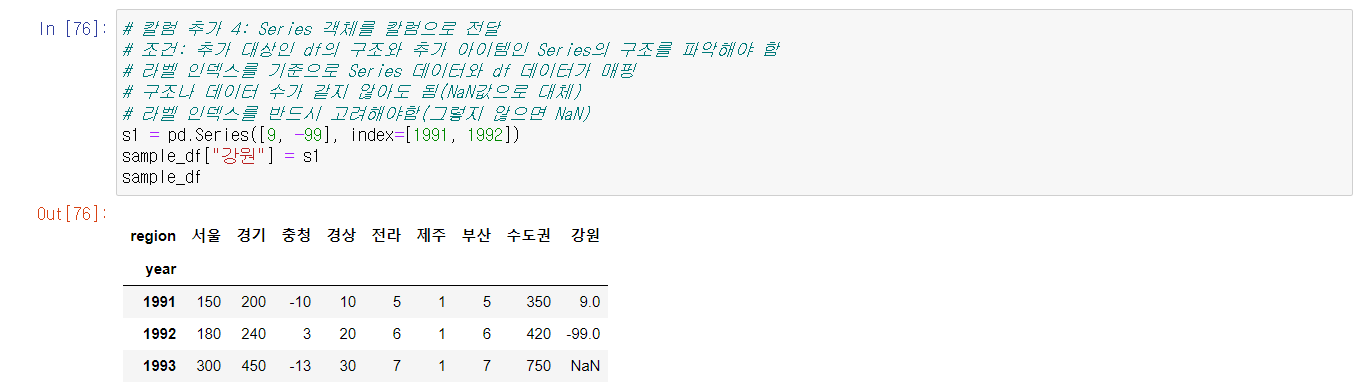
또한 DataFrame에 row와 column 자체를 추가할 수 있고, 또한 값도 지정해서 추가할 수 있다.

실습하면서 어려웠던 것들을 캡쳐했다.
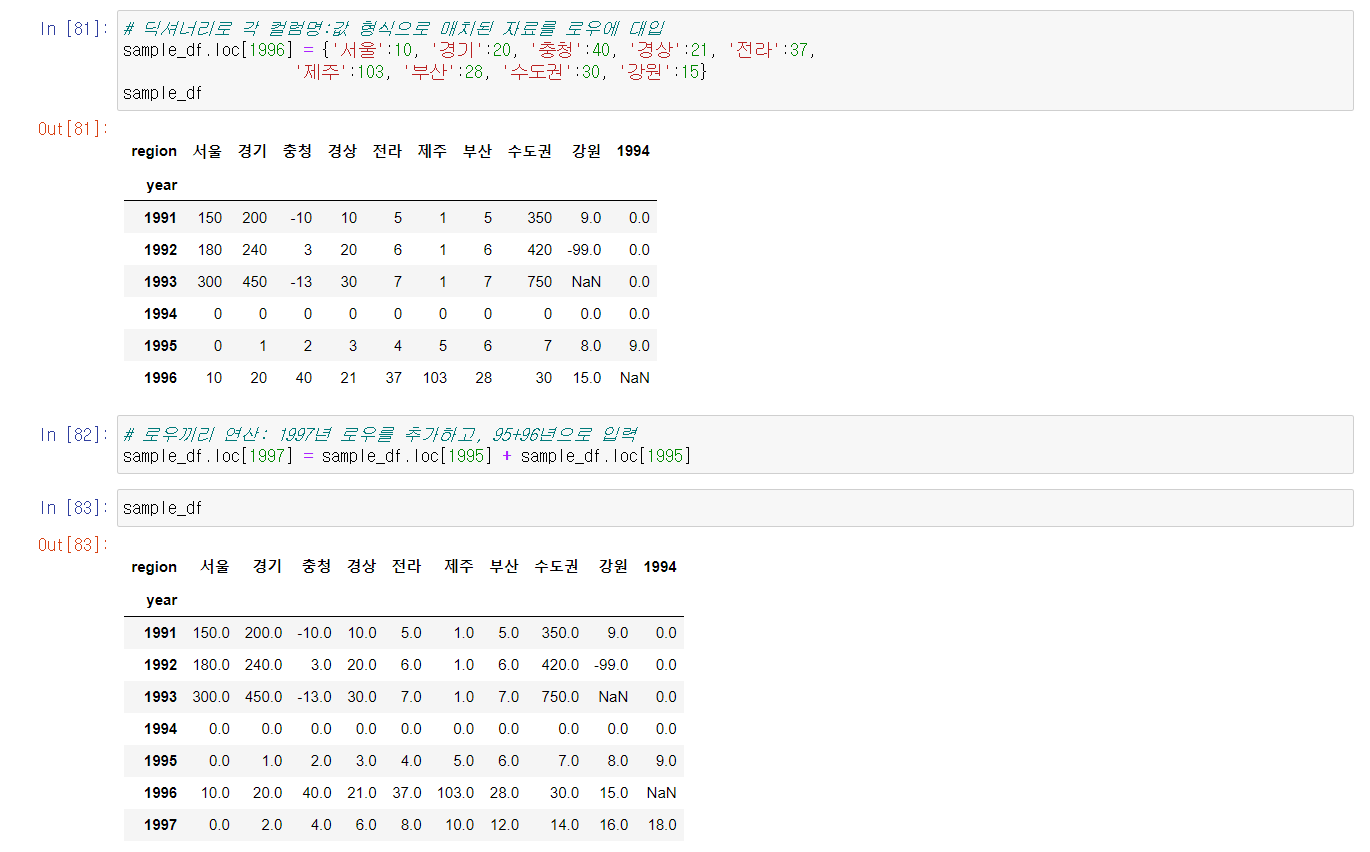
또한, Series와 마찬가지로 DataFrame 또한 산술연산이 가능하다.

DataFrame간 row와 column의 개수가 달라도 연산은 가능하지만, 그 경우 둘 모두에 존재하지 않는 row와 column은 NaN값으로 표기된다. 이를 방지하기 위해서는 fill_value인자를 주면 된다.
DataFrame과 Series간 연산도 가능한데, 이 경우에는 연산하려는 Series의 라벨 인덱싱과 DataFrame의 row 혹은 column의 이름이 같아야 한다. 그렇지 않을 경우 공통 이름이 아닌 데이터에 대해서는 NaN값으로 표기되는데, Series와 DataFrame간 연산의 경우 fill_value인자를 사용할 수 없음에 주의해야 한다.

'Python' 카테고리의 다른 글
| Day 15 - 데이터 전처리 및 기초 데이터 통계 실습 (0) | 2022.10.25 |
|---|---|
| Day 14/15 - Pandas (3) (0) | 2022.10.24 |
| Day 12/13 - Pandas (0) | 2022.10.20 |
| Day 12 - Numpy (6) (0) | 2022.10.20 |
| Day 12 - Numpy (5) (0) | 2022.10.20 |