2022. 10. 20. 17:51ㆍPython
이번 글에서는 파이썬의 라이브러리 중 하나이고, 데이터분석에 널리 쓰이는 Pandas의 기본적인 내용에 대해 정리할 것이다. Pandas의 경우 데이터분석에서 아주 큰 역할을 하는데, 이는 근본적으로 Pandas가 데이터 처리와 분석을 위해 만들어졌다는 점에서 기인한다.

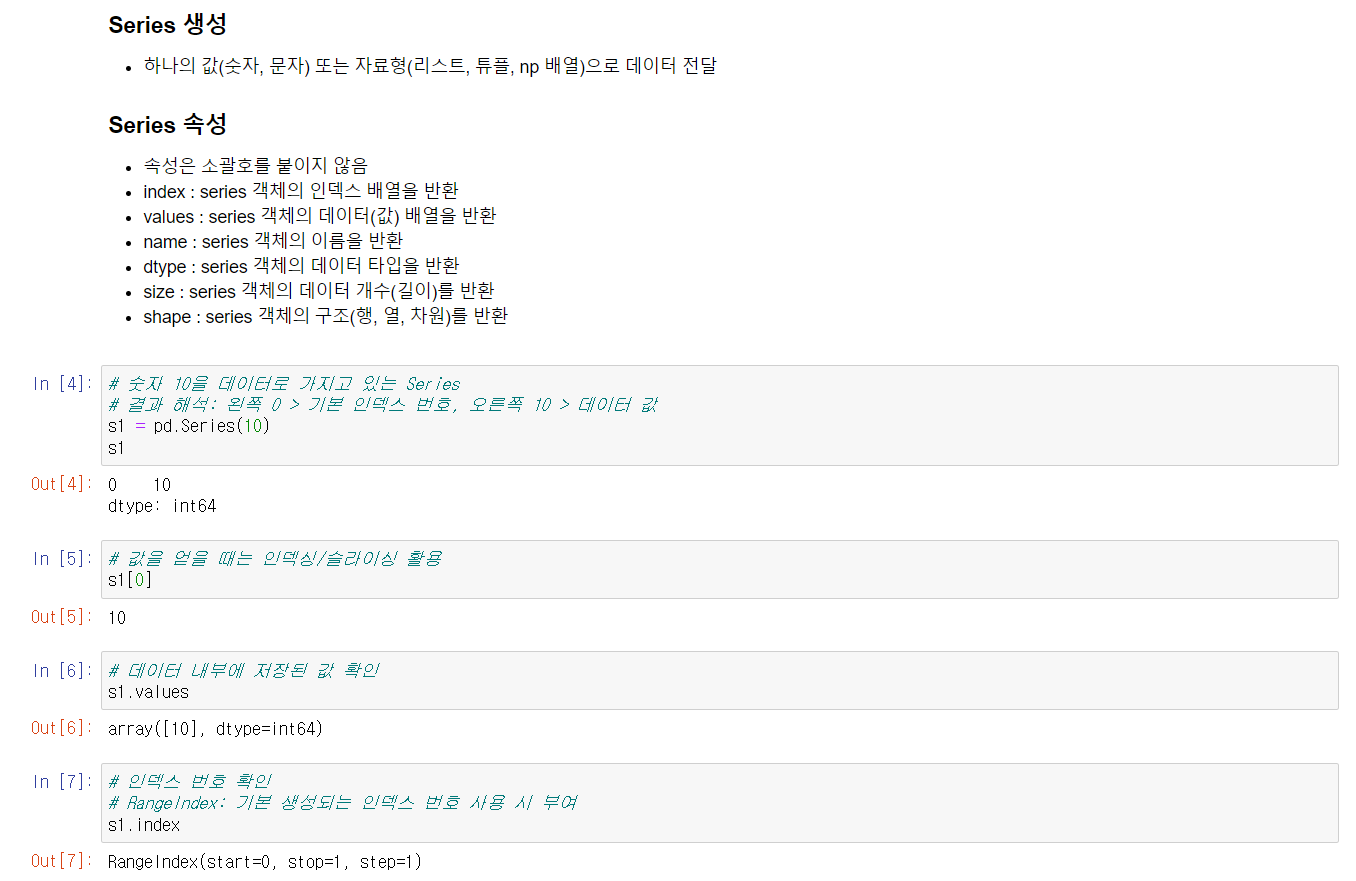
Pandas의 데이터타입에는 우선 Series가 있다. Series의 경우 여러가지 데이터타입을 사용할 수 있으며, 속성을 알아보는 함수가 소괄호를 붙이지 않는 점에 유의하자.
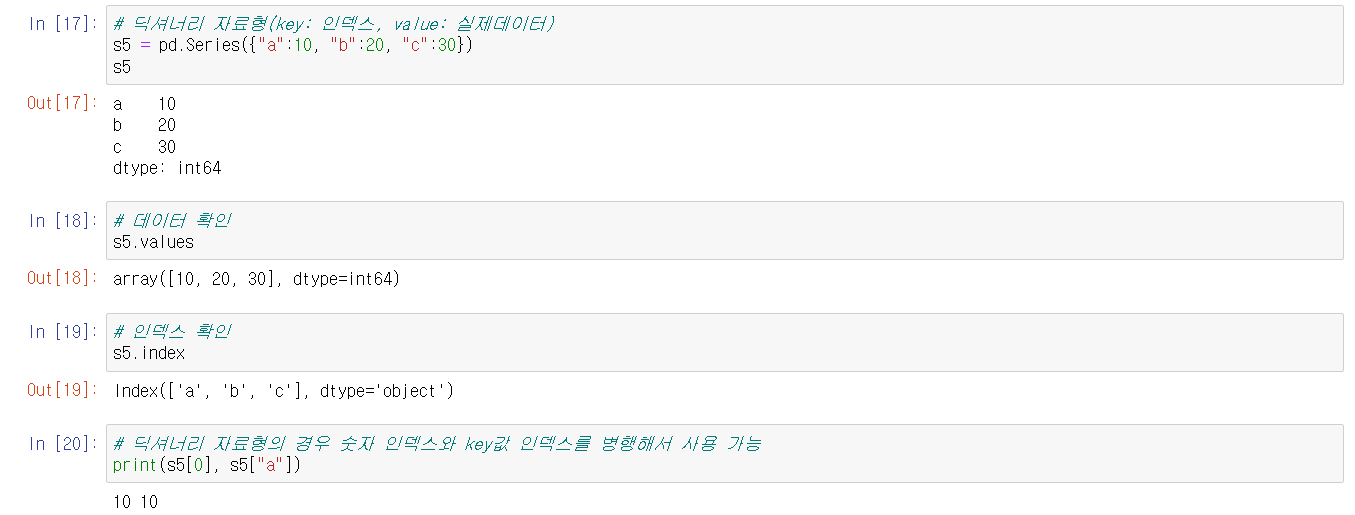
딕셔너리 자료형이 Series화 될 경우, key값이 인덱스로, value값이 실제 데이터로 자동으로 라벨링 된다는 것을 잘 기억하자.
한 편 Series 자료형의 경우 인덱스도 사용자가 지정하고 수정할 수 있고, 인덱스를 수정해도 기본 인덱스 번호는 여전히 사용할 수 있다. 또 생성시 index 파라미터를 활용해서 딕셔너리를 활용하지 않고도 인덱스를 지정하는 것이 가능하다.
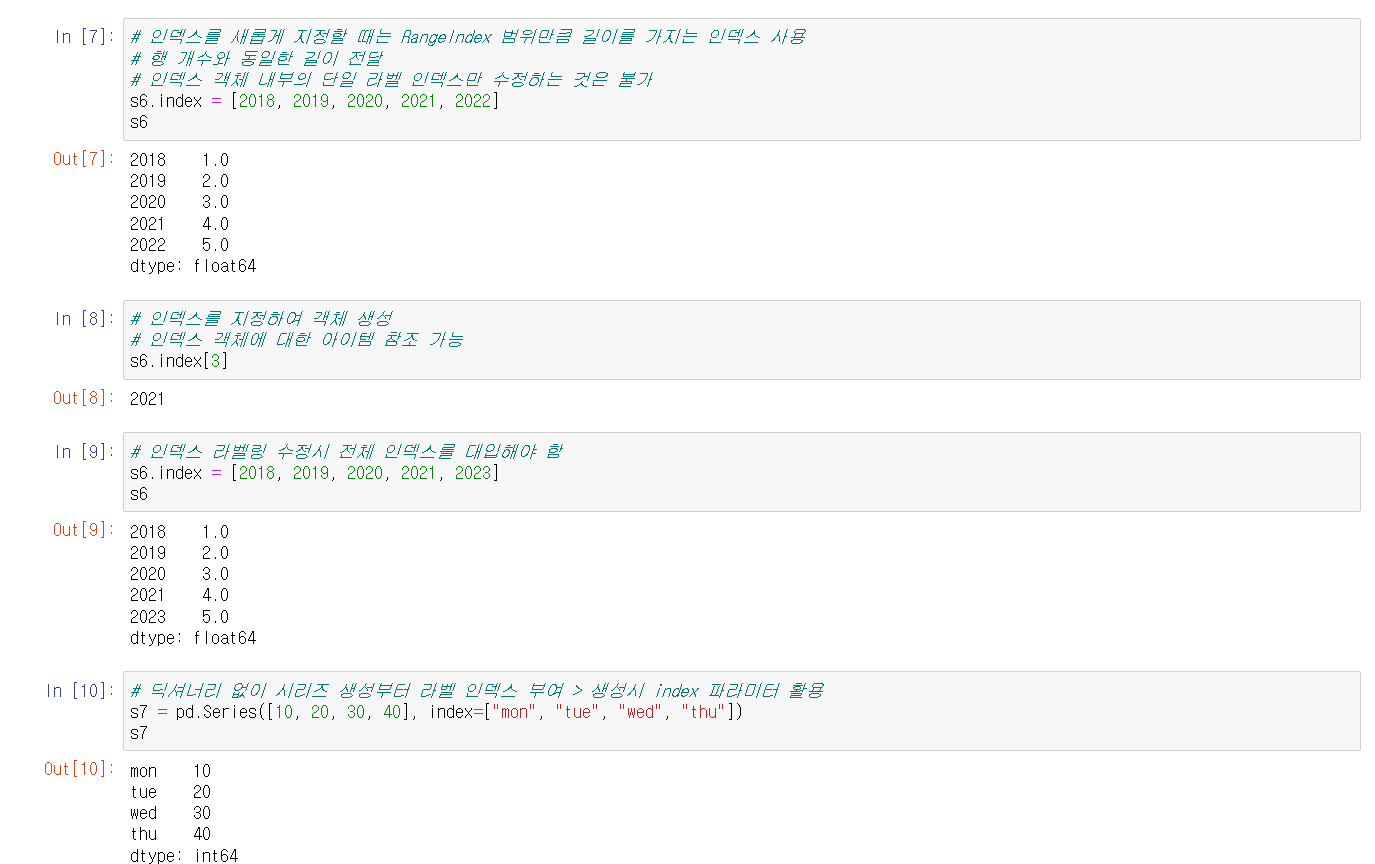
하나의 인덱스 라벨링을 수정하고 싶어도 전체 인덱스를 대입해야 한다는 것을 알아두자.
또한 Series 자료형의 경우 dictionary 자료형과 비슷하니, 알아두면 좋을것 같다.
한편 Series 자료형에도 다른 대부분의 자료형과 마찬가지로 인덱싱과 슬라이싱을 사용할 수 있다.


인덱싱을 통해 원하는 행만 조회할 때는 조회하고 싶은 행의 이름을 리스트로 묶어서 전달해서, 2차원 리스트를 활용하면 된다는 것을 알아두자.
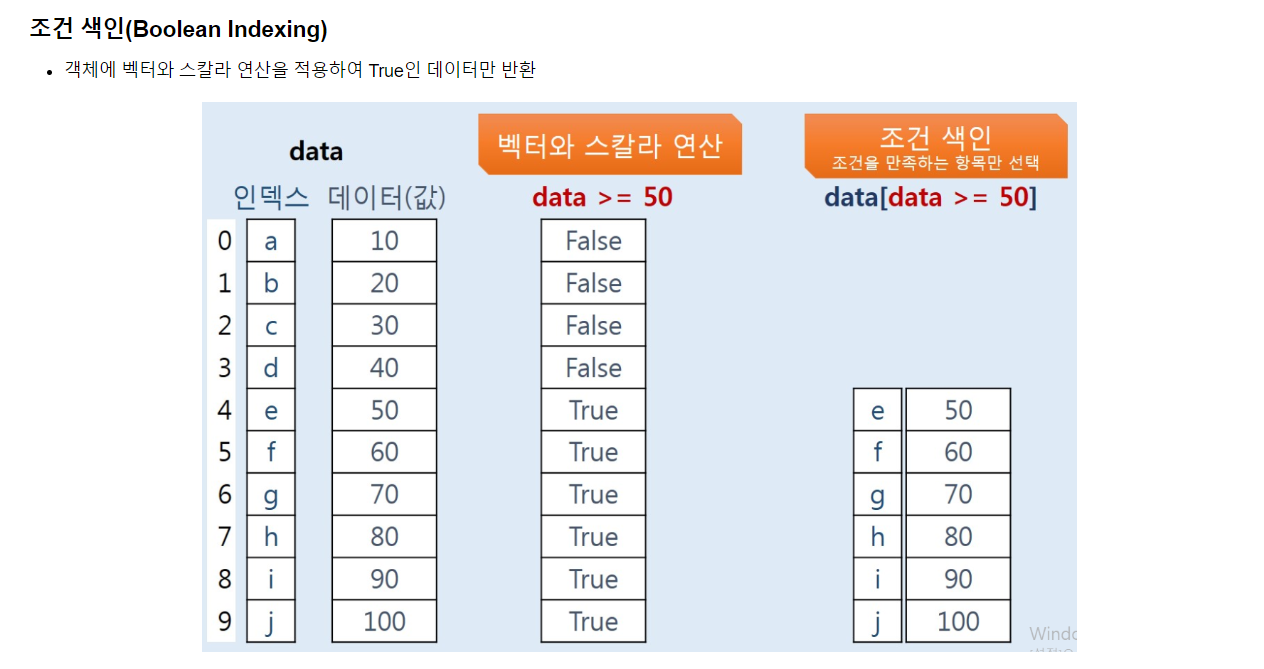
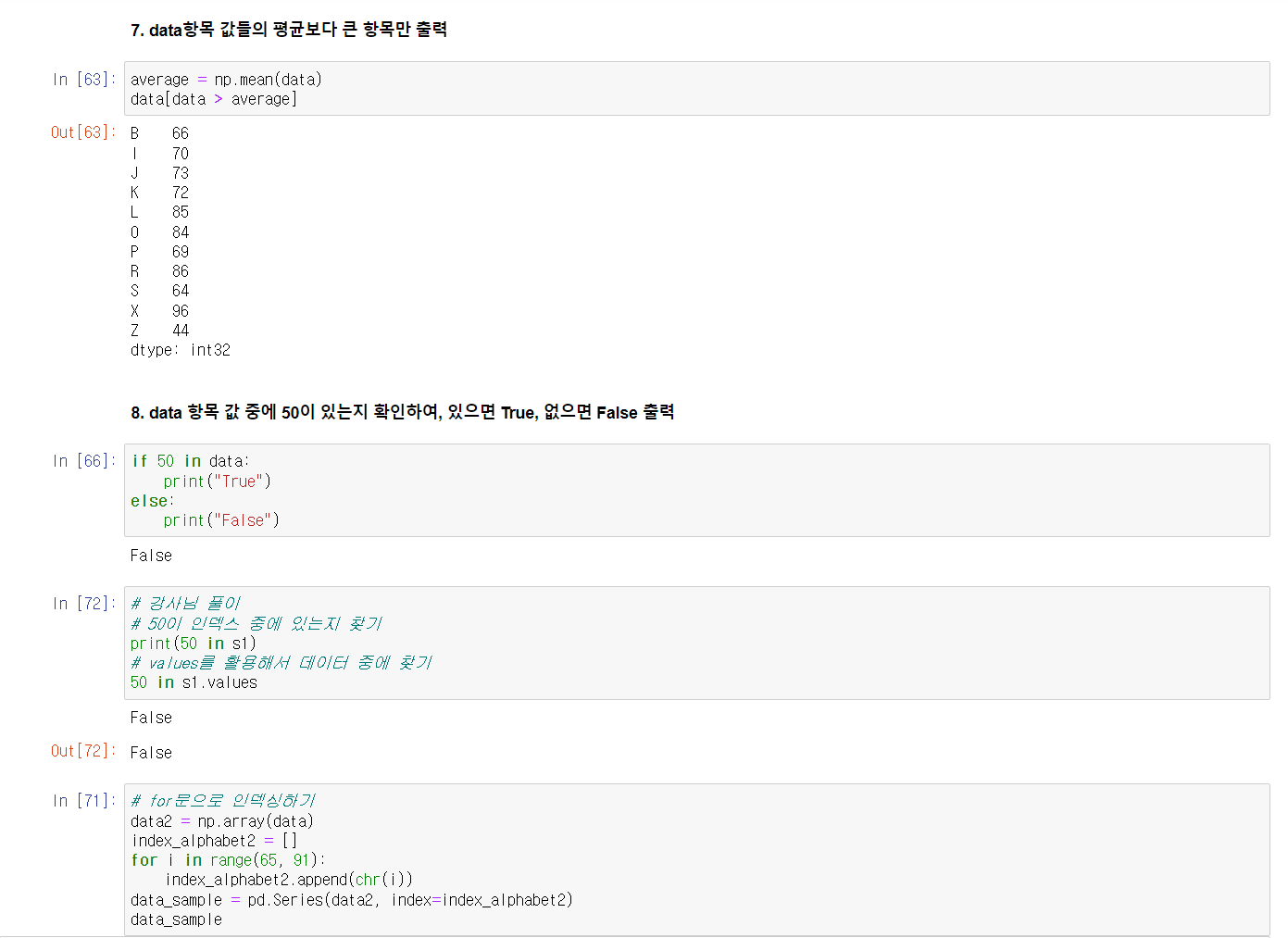
또한 Series에서도 조건 색인이 가능하고, array에서와 마찬가지로 두 개 이상의 조건을 거는 것도 가능하다.
이에 더해, Series 자료형에도 연산을 할 수 있다. 단, Series 객체 간의 연산에서 라벨이 같지 않으면 해당 라벨에는 NaN 밸류값이 주어진다.
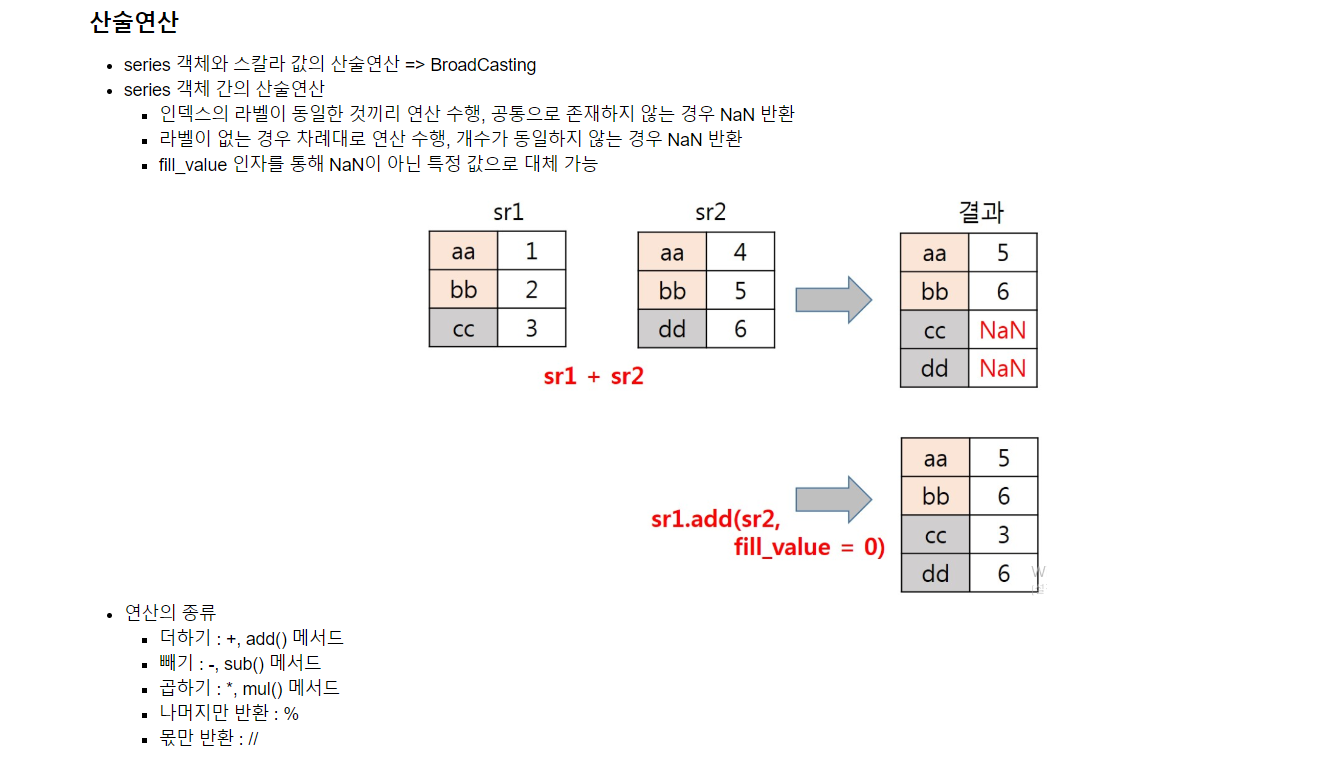
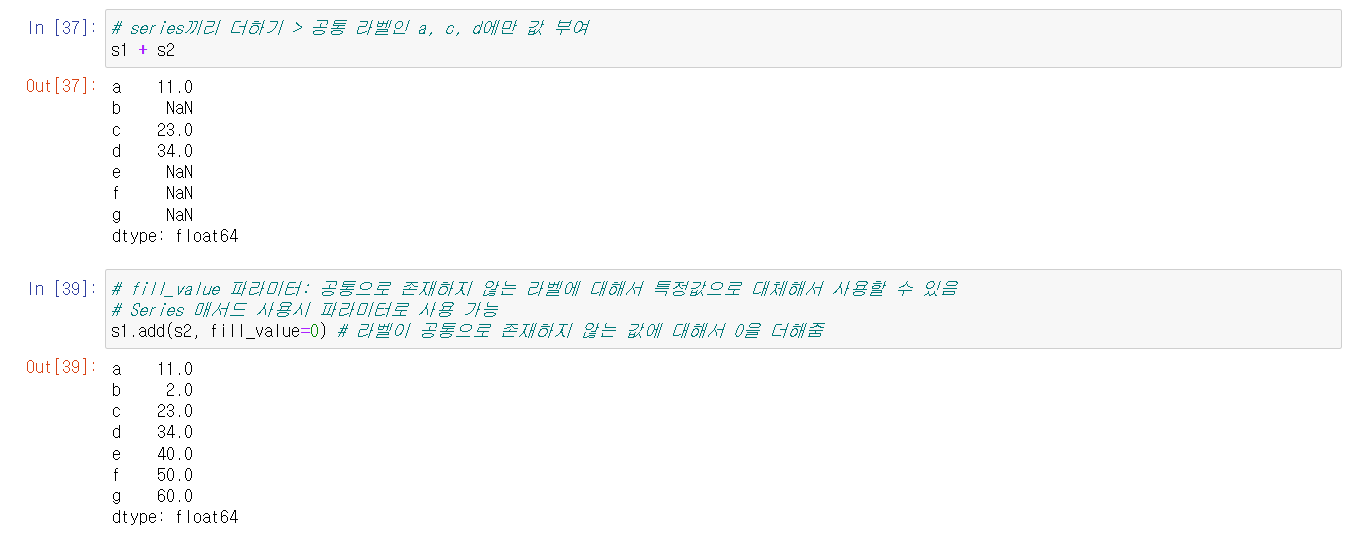
이렇게 NaN값이 출력되는 문제를 Series의 연산 메서드에 fill_value 파라미터를 주어 해결할 수 있다. 단 기존과 같은 값을 얻고 싶다면 덧셈과 뺄셈 시에는 0, 곱셈과 나눗셈 시에는 1을 각각 인자로 주어야 한다.
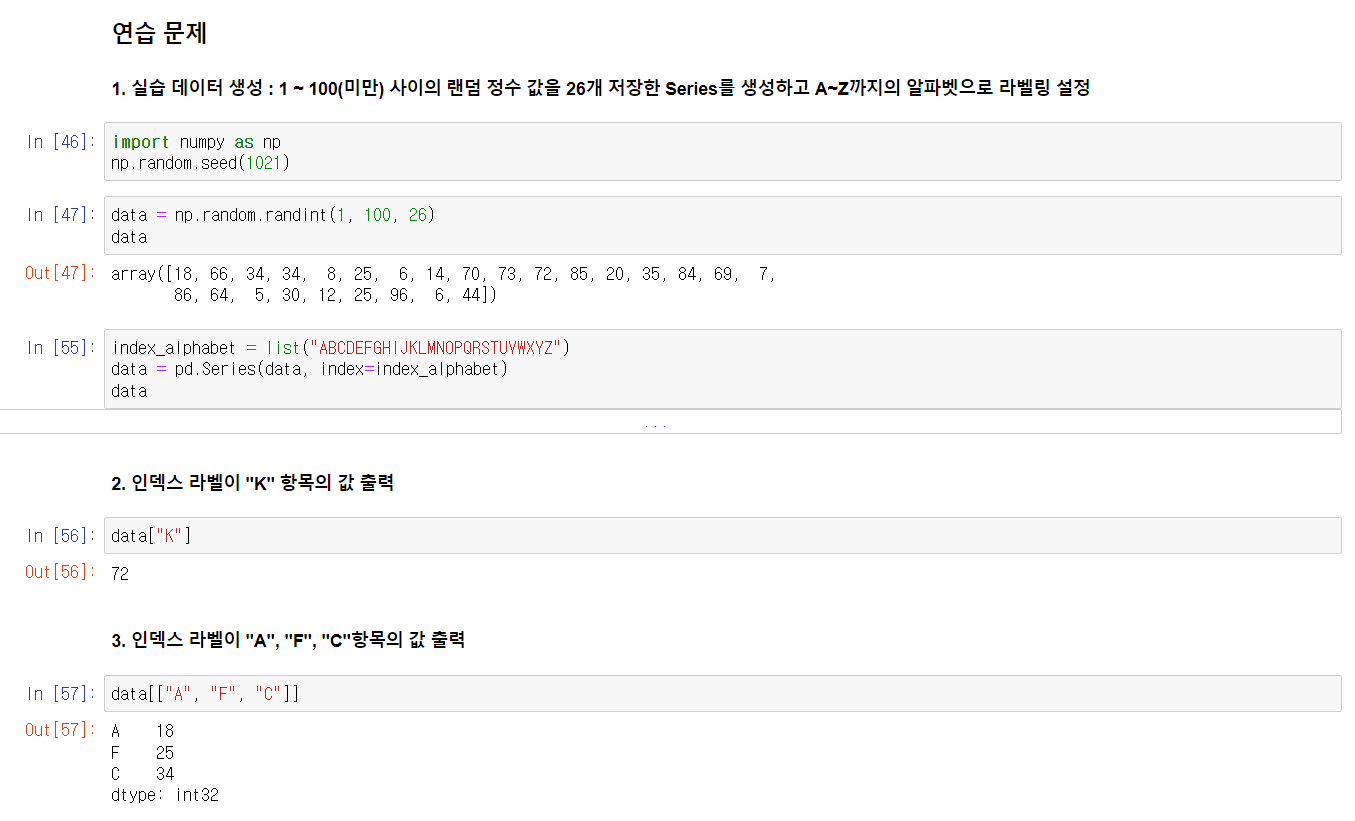
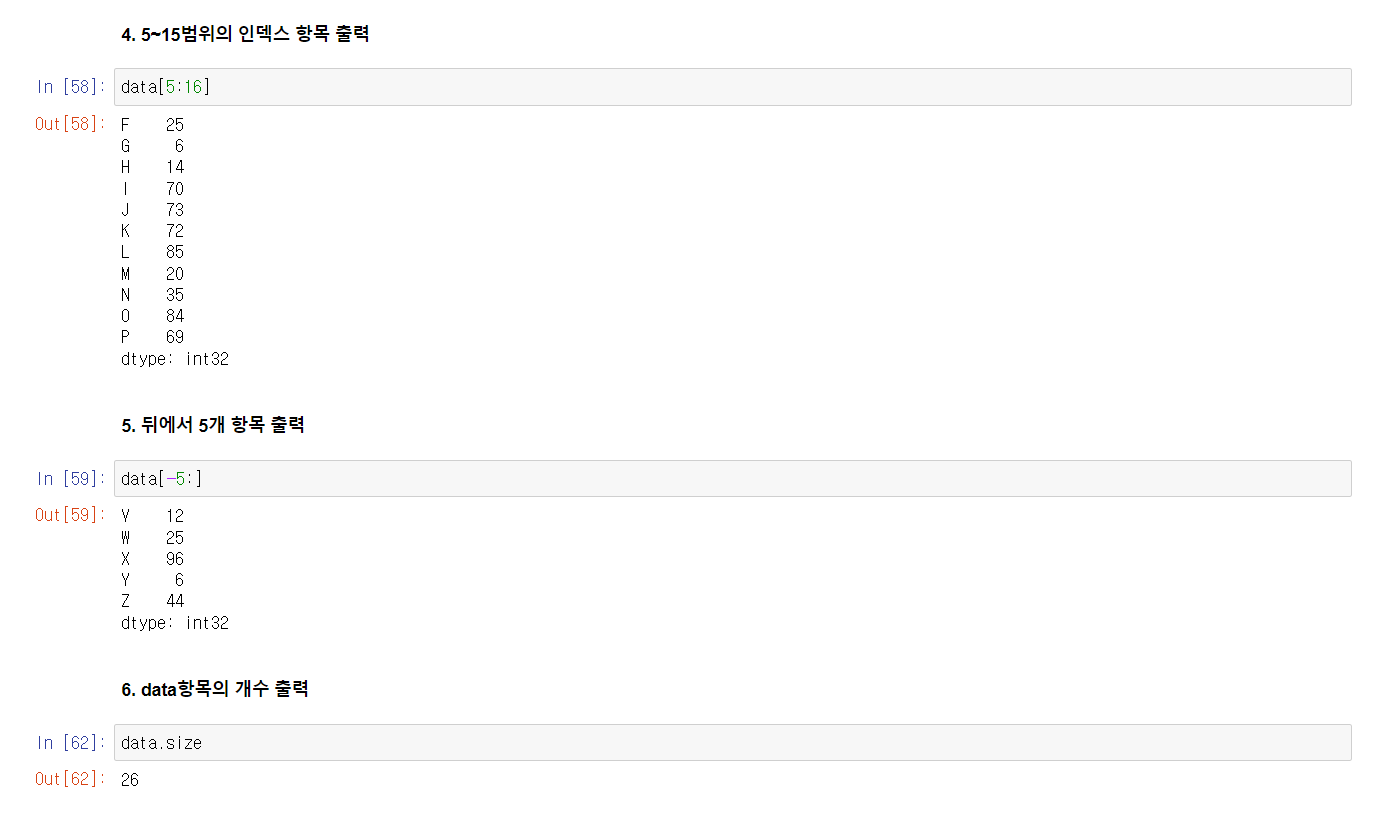
Series의 데이터 인덱싱 관련 연습문제를 풀었다.
'Python' 카테고리의 다른 글
| Day 14/15 - Pandas (3) (0) | 2022.10.24 |
|---|---|
| Day 13/14 - Pandas (2) (0) | 2022.10.21 |
| Day 12 - Numpy (6) (0) | 2022.10.20 |
| Day 12 - Numpy (5) (0) | 2022.10.20 |
| Day 12 - Numpy (4) (0) | 2022.10.20 |