2022. 10. 12. 17:04ㆍPython
오늘은 파이썬을 이용해 데이터 크롤링을 하는 방법을 배웠다. 이번 글에서는 크롤링을 위한 준비 사항과 기초적인 크롤링에 대해 정리할 것이다.
우선 크롤링을 하기 위해 파이썬에 몇 가지 모듈을 import 해야 한다. 또한 크롤링에 이용할 브라우저의 드라이브를 다운 받아야 하는데, 이번 크롤링은 엣지로 진행했기 때문에 Edge Drive를 다운 받았다.
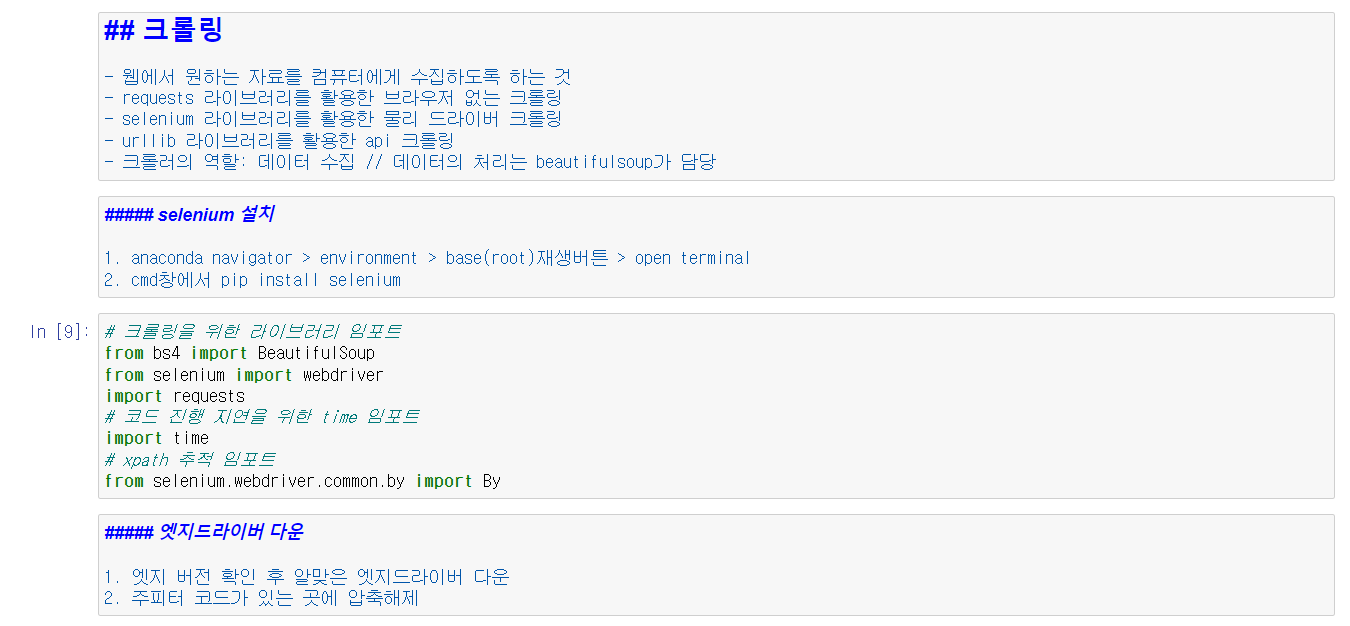
모듈과 드라이버를 모두 설치 및 import한 뒤, driver 변수를 통해 엣지 브라우저를 제어해보았다.

driver변수에 쓰이는 .get(), .find_element() 등에 대해 익숙해지도록 하자.
위에서 배운 내용을 이용하여 네이버 검색창을 이용하여 교보문고 사이트에 접근하는 실습을 했다.

한 편, 웹사이트에 접근할 때는 접근방식을 신중하게 선택해야 하는데 그 이유는 사이트마다 구동방식이나 만족해야 하는 조건들이 다르기 때문이다.

크롤링의 궁극적인 목표는 크롤링한 데이터를 정제하고 분석하여 사용자가 원하는 데이터를 만드는데 있다. 크롤링에서 데이터의 정제와 분석을 위해 BeautifulSoup 모듈을 사용한다. 교보문고 사이트를 통해 실습해보았다.

BeautifulSoup로 데이터를 정제하기 이전에 Selenium을 통해 크롤링한 소스코드를 문자열에서 html문으로 파싱해주는 작업이 꼭 필요하다.
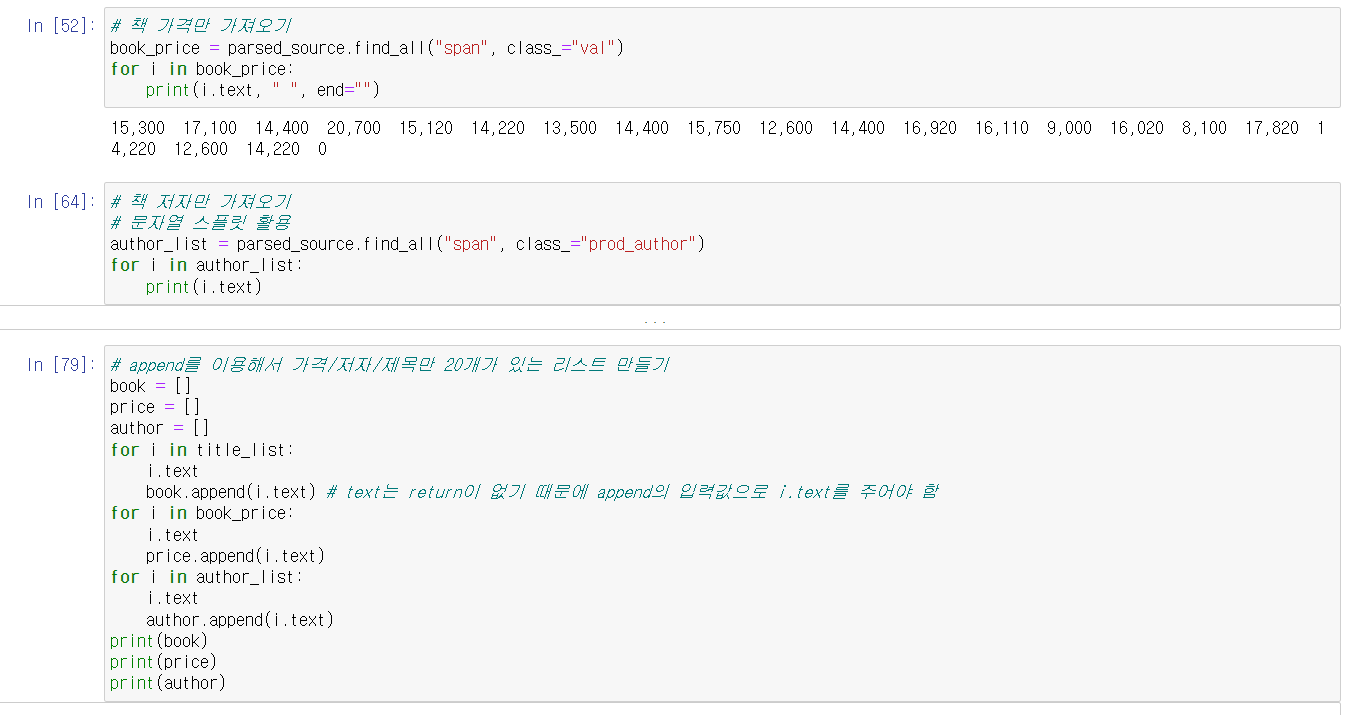
이에 더해, .find_all()을 통해 정제한 데이터의 경우 리스트 형식이기 때문에, 리스트 내부의 아이템을 수정하기 위해 인덱싱이 필요하다. 아이템의 태그를 제거하고 싶다면 .text를 사용하면 된다.

위에서 배운 내용을 활용하여 교보문고 베스트셀러 1-20위까지의 책 가격과 저자/출판사/출시일만 가져와 보았다.
알라딘의 경우 교보문고에 비해 크롤링이 어려운 편이라고 하셔서 한 번 제목만 가져와 보았는데, 강사님께서는 find_all()을 적용한 것에 추가로 find_all()을 써서 할 수 있다고 하셨지만 어떻게 추가적으로 사용할 수 있는지 알 수 없어서 그냥 배운 내용만으로 해 보았다.

'Python' 카테고리의 다른 글
| Day 7 - 크롤링 (2) (0) | 2022.10.13 |
|---|---|
| Day 6 - codecs 라이브러리 (0) | 2022.10.12 |
| Day 5 - 파이썬의 함수 (2) (0) | 2022.10.11 |
| Day 5 - 파이썬의 함수 (0) | 2022.10.11 |
| Day 5 - 파이썬 제어문 연습문제 풀이 (0) | 2022.10.11 |