Day 23/24 - 머신러닝 5 > 결정 트리 (Decision Tree)
이번 글에서는 머신러닝 알고리즘 중 하나인 결정 트리에 대해 정리할 것이다.
결정 트리는 각 변수의 특정 지점을 기준으로 데이터를 쪼개가면서 예측 모델을 만드는 알고리즘으로, 트리 기반 모델의 기본 모델이다. 다른 트리 기반 모델에 비해 예측력과 성능이 떨어지지만 다른 모델을 이해하기 위해 필요하며, 시각화에 용이하다. 종속변수의 데이터 타입에 관계 없이 사용 가능하며, 아웃라이어에 영향을 거의 받지 않는다는 장점이 있지만, 트리의 깊이가 너무 깊어지면 오버피팅이 발생할 위험성이 크다는 단점이 있다.
Kaggle의 Salary 데이터를 활용하여 실습을 진행했다.
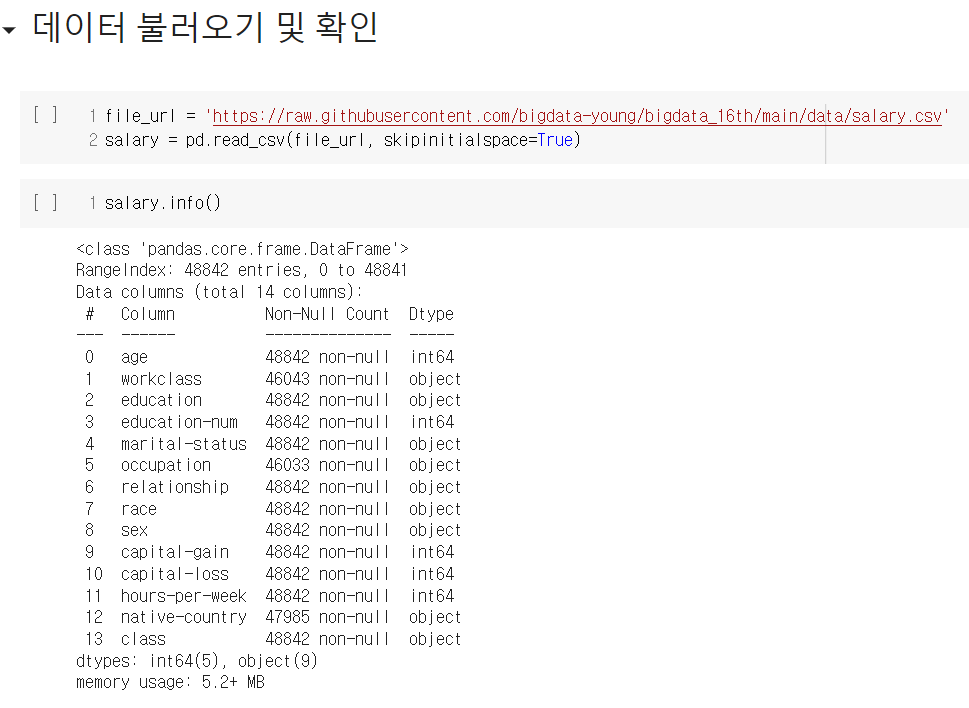
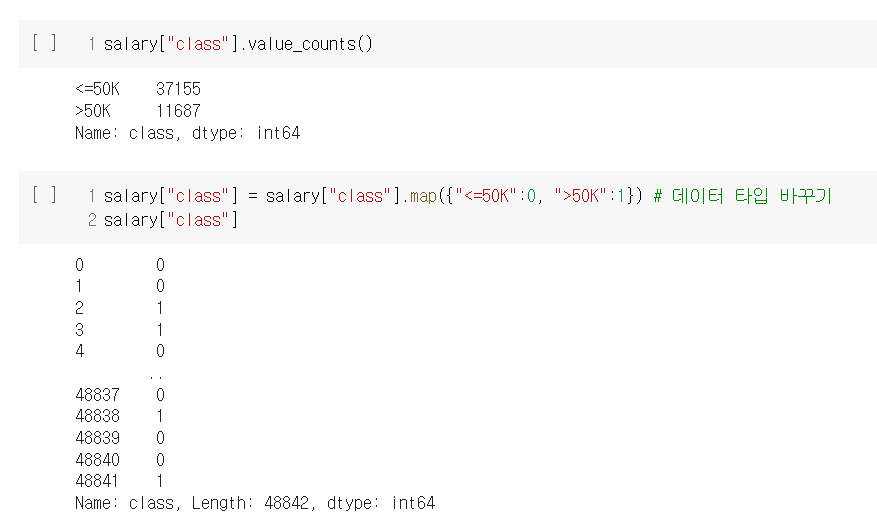
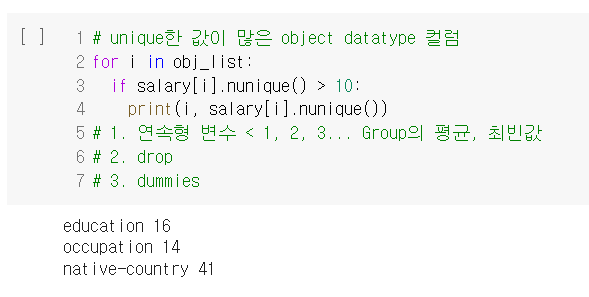
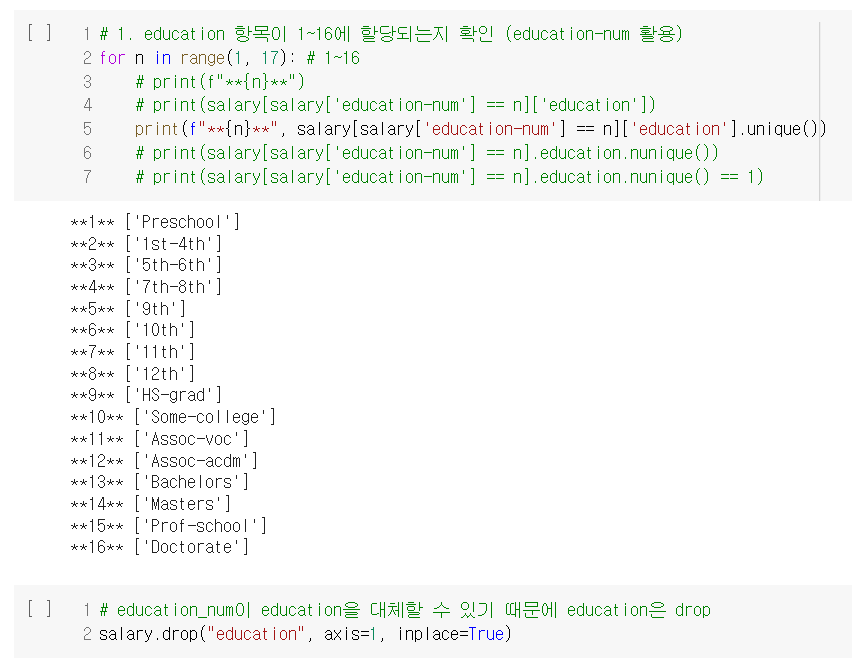




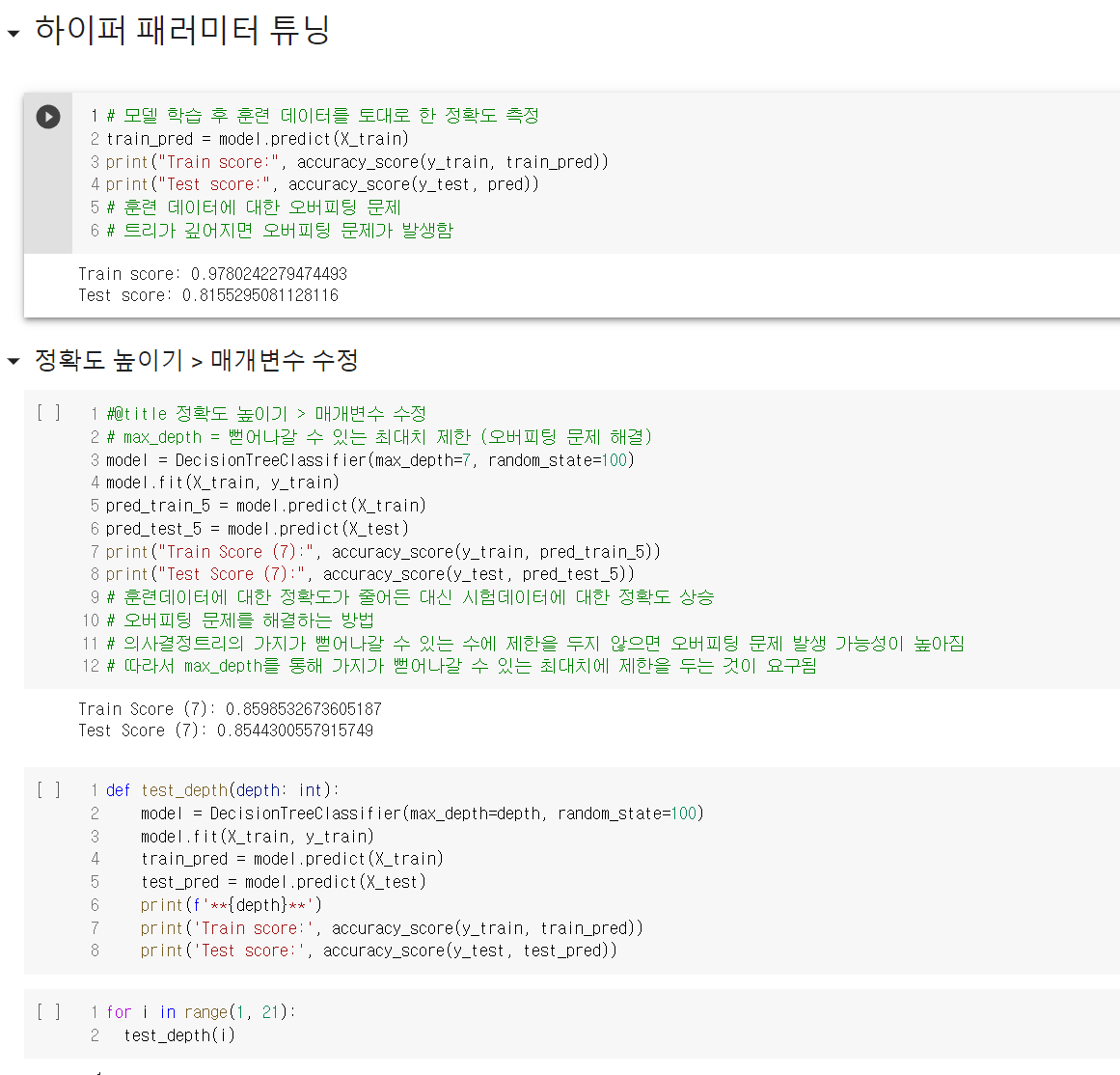
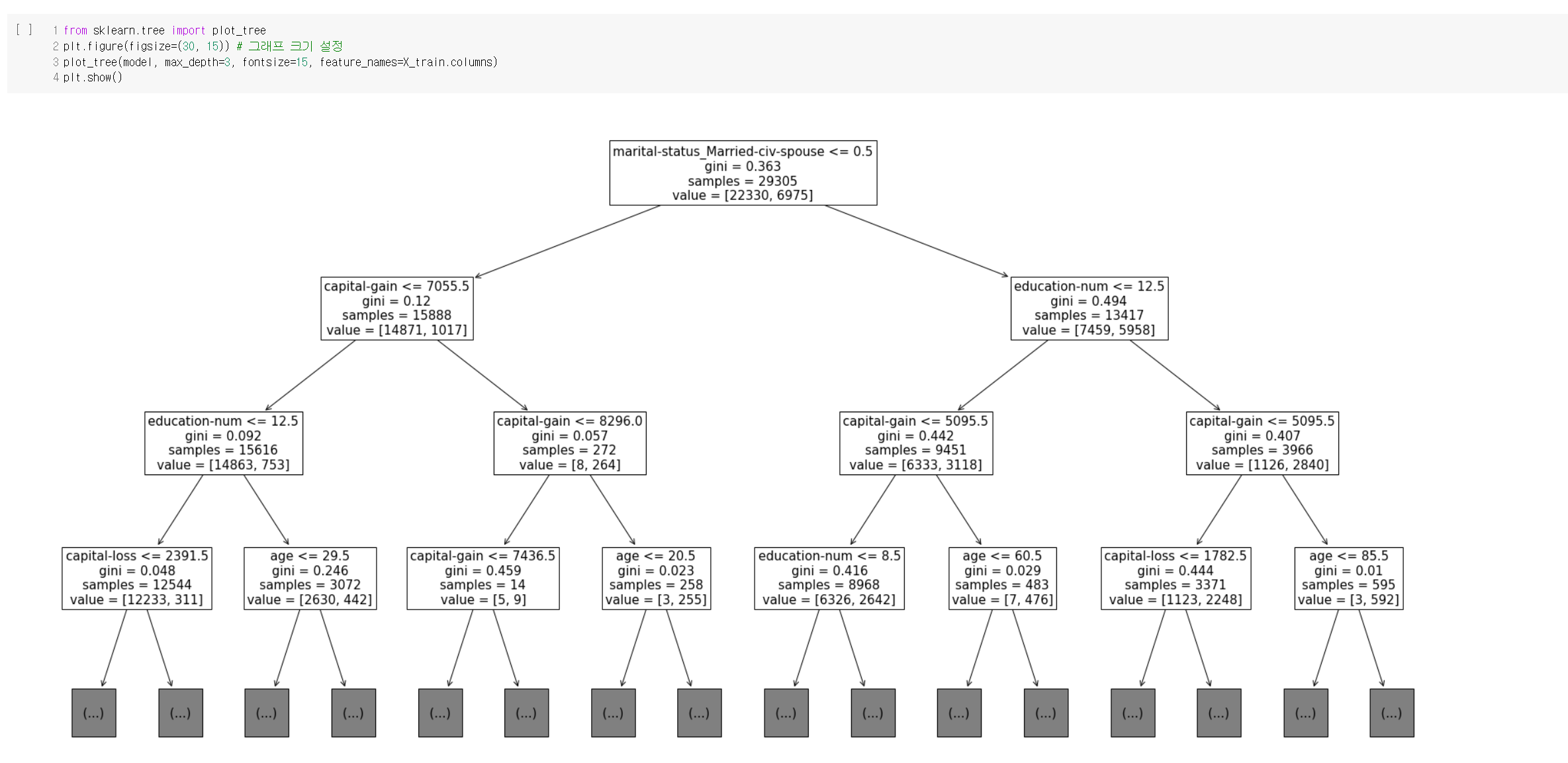
결정 트리의 장점과 단점을 너무나 잘 알 수 있는 실습이었다. 설명력이 높고 시각화에 유용하다는 장점도 확인했고, 오버피팅 문제가 일어나기 쉽다는 단점도 확인했다. 그 외에는, 역시 데이터 분석 과정에서 데이터 전처리 작업이 제일 지난하고, 또 제일 중요하다는 사실을 다시 한 번 깨달았다.