2022. 11. 17. 17:27ㆍPython
이번 글에서는 딥러닝에 대해 정리할 것이다.
딥러닝은 머신러닝 알고리즘 중 하나로, 인공신경망에서 진화한 형태이다. 주로 이미지, 자연어, 비디오 분석에 많이 활용되고 대표적인 프레임워크로는 텐서플로우(TensorFlow), 케라스(Keras), 파이토치(PyTorch) 등이 있다.
딥러닝도 머신러닝의 일종이기 때문에 프로세스 역시 머신러닝과 비슷하다.
- 딥러닝 프로세스
문제 정의 ➡ 데이터 수집 ➡ 데이터 전처리 ➡ 딥러닝 모델 설계 ➡ 모델 학습 ➡ 성능 평가
딥러닝에 대해 이해하기 위해서는 인공신경망에 대한 이해가 필요하다. 인공신경망이란, 사람의 신경망을 본떠 만든 알고리즘으로 퍼셉트론을 사용하여 만든다. 여기서 퍼셉트론은 인간의 뇌세포를 수학적으로 표현한 알고리즘으로 인공 뉴런이라고도 한다. 이 퍼셉트론을 하나만 사용한 인공신경망은 단층신경망이라고 하고, 여러 개 사용한 것은 다층신경망 또는 완전신경망이라고 한다.
- 퍼셉트론
- 입력층, 노드, 출력층으로 구성된다.
- 입력값에 가중치를 곱해 더해준 다음, 활성화 함수를 이용해 다음 노드에 정보 전달 여부를 결정한다.
- 가중치는 입력의 중요도를 나타내며, 더해지는 편향은 활성화 함수의 임계값을 이동시킨다.
- 출력값은 활성화를 거친 후 얻어지는 값이다.
- 활성화 함수는 임계값을 기준으로 노드의 출력값을 결정하는 함수로, 이 함수로 인해 층을 쌓는 효과가 생긴다.
- 활성화 함수의 입력으로는 가중합이 사용된다.
- 활성화 함수로는 주로 시그모이드 함수가 쓰이는데, 이는 인공 신경망의 출력을 확률로서 다루기 위해서이다.
- 단층신경망
- 다양한 데이터를 분류할 수 있지만 모든 형태의 데이터에 대해 분류할 수 없어서 다층신경망을 사용한다.
- 다층신경망
- 입력층, 은닉층, 출력층으로 구성된다.
- 입력층은 데이터가 입력되는 층이다.
- 은닉층은 입력값이 바뀌는 곳으로, 값을 출력할 필요가 없어 출력하지 않기 때문에 은닉층이라고 한다. 이 때 하나의 층에서 노드의 수를 층의 너비라고 하고, 층의 개수를 층의 깊이라고 한다.
- 출력층은 데이터의 출력을 결정한다.
- 이렇게 데이터가 입력층 ➡ 은닉층 ➡ 출력층의 방향으로 전달되는 것을 순전파라고 한다.
인공신경망의 모델 평가, 곧 성능 비교는 오차가 얼마나 작은지가 핵심이다. 계산하기 비교적 쉬운 단층신경망에서는 MSE, RMSE 등의 손실함수를 사용하지만, 다층신경망은 계산하기 어렵기 때문에 경사하강법, 오차역전파 등의 방법을 사용하여 인공신경망의 성능을 평가하고 또 향상시킨다.
- 경사하강법: 손실을 줄이는 방향으로 가중치를 수정하기 위한 알고리즘으로, 오차 함수의 기울기를 구한 뒤 경사의 반대방향으로 이동시켜서(즉 -1을 곱한다는 뜻이다.) 해당 기울기가 최소값이 될 때까지 반복하는 방법이다.
- 오차역전파: 마찬가지로 오차를 최소화하는 가중치를 찾는 알고리즘으로, 오차를 역전파, 즉 출력층부터 입력층까지 전달해서 출력층의 가까운 가중치부터 수정한다. 미분의 연쇄 법칙을 활용한다. 이 오차역전파 알고리즘은 기울기 손실 문제가 일어날 수 있다.
- 기울기 손실 문제: 오차가 역전파 될 때마다 활성화 함수로 쓰이는 시그모이드 함수의 도함수가 곱해진다. 시그모이드 함수의 도함수 최대값이 0.25이기 때문에 역전파 되어서 층을 지날 때마다 오차가 점점 줄어들게 된다. 이 때문에, 층이 너무 깊어지면 입력층에 가까운 은닉층은 학습이 제대로 이루어지지 않고, 시그모이드 함수 특성상 기울기도 0에 계속 가까워지게 된다.
- 이 문제를 해결하기 위해 미분해도 값이 줄어들지 않는 ReLU와 같은 활성화 함수를 사용한다.
- 오버피팅 문제가 일어날 수 있기 때문에 평가용 데이터로 검증한다.
여러가지 방법과 데이터셋을 통해 딥러닝을 실습해보았다.
1. 사인함수 예측 실습
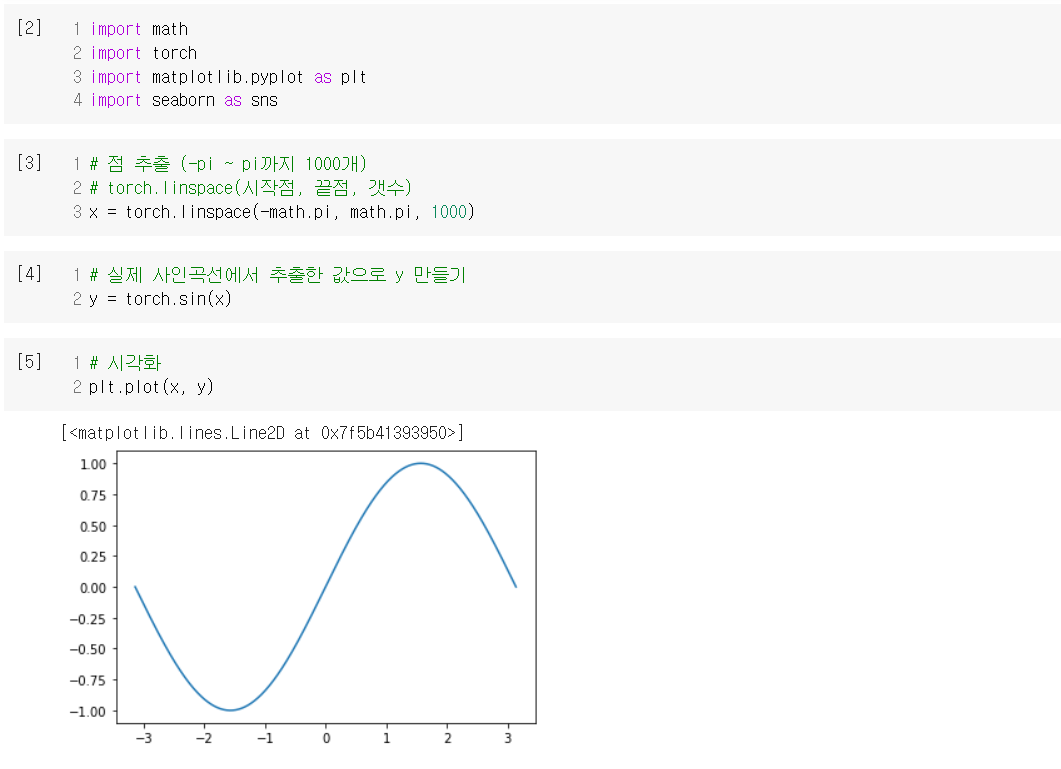
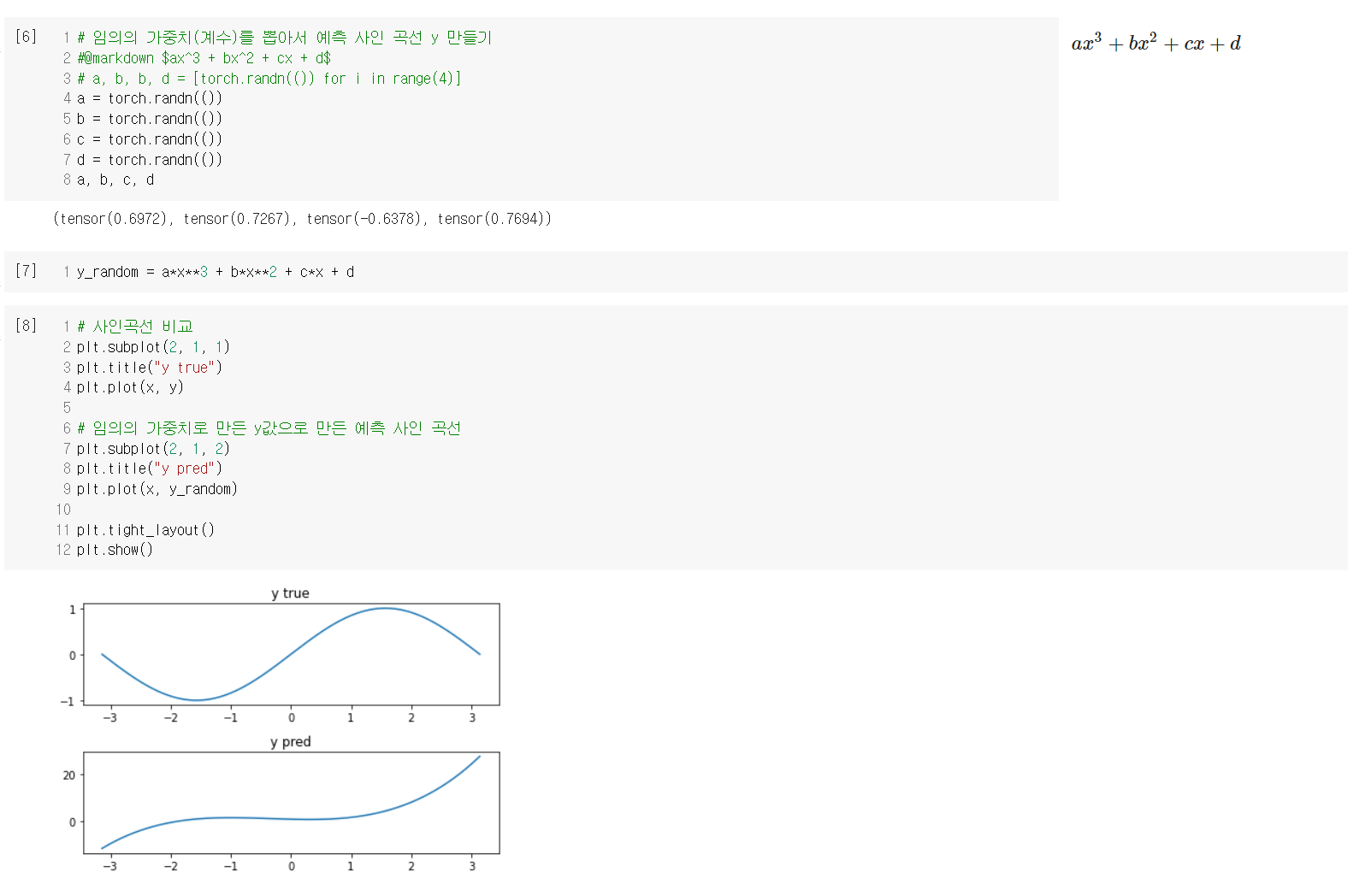

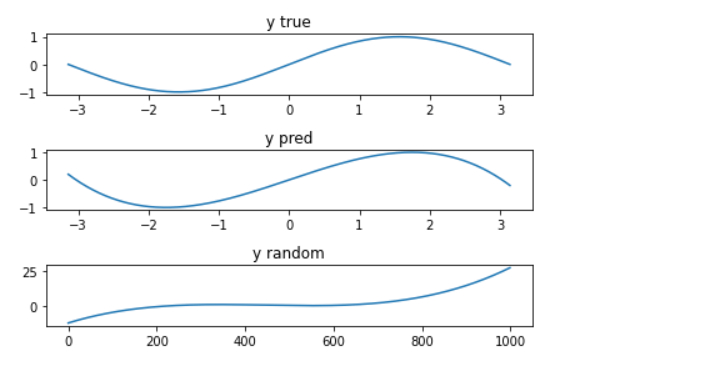
이 실습을 통해, 딥러닝이 좋은 툴이라는 것을 알 수 있었다.
2. 보스턴 집값 데이터
유명한 데이터셋 중 하나인 보스턴 집값 데이터를 통해 딥러닝 실습을 진행했다.
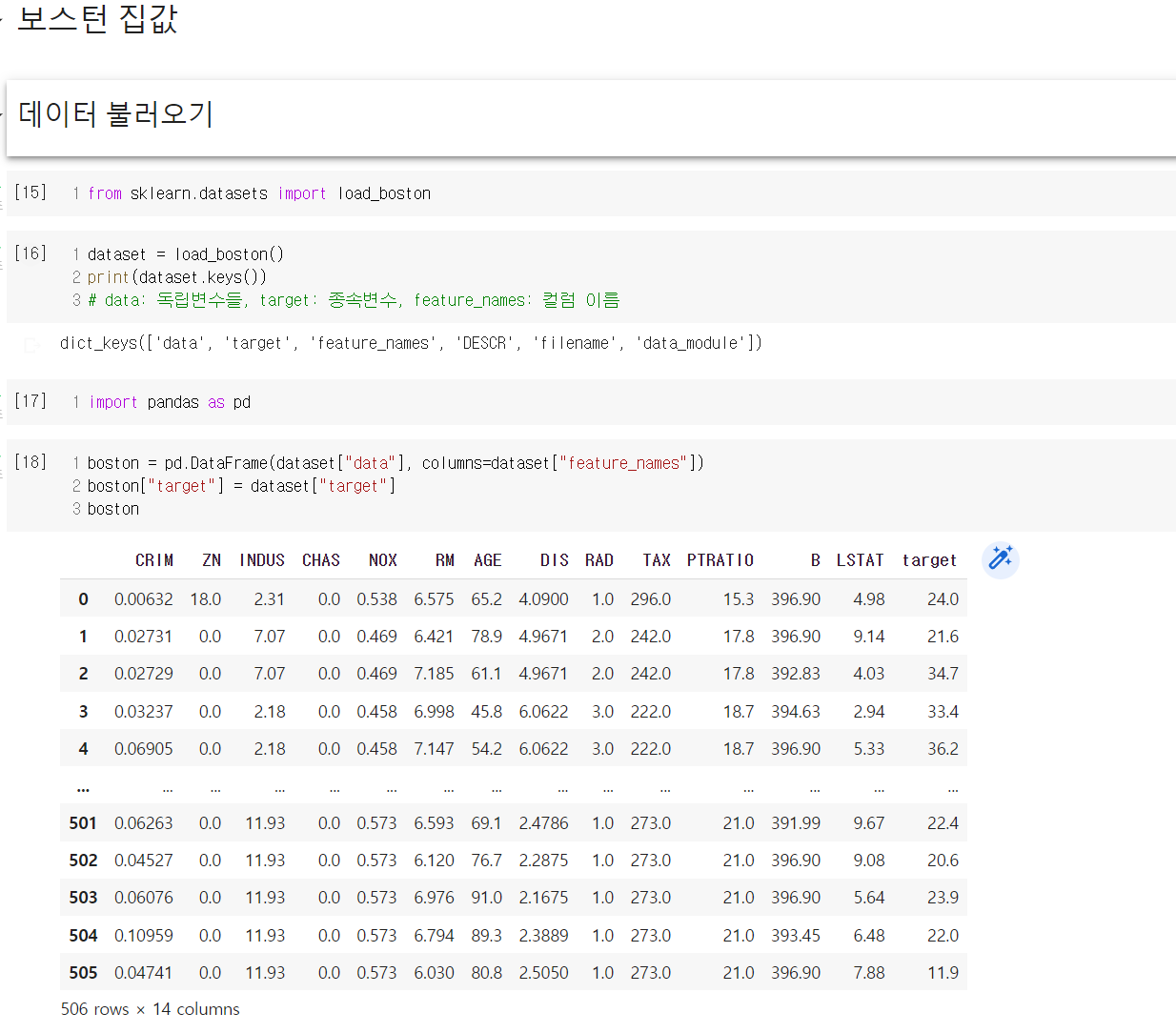

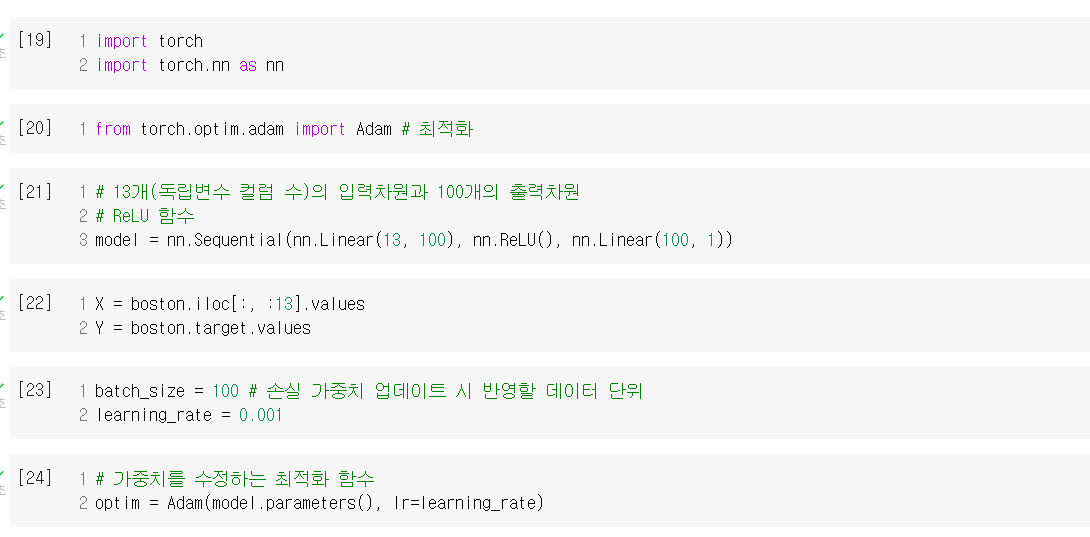
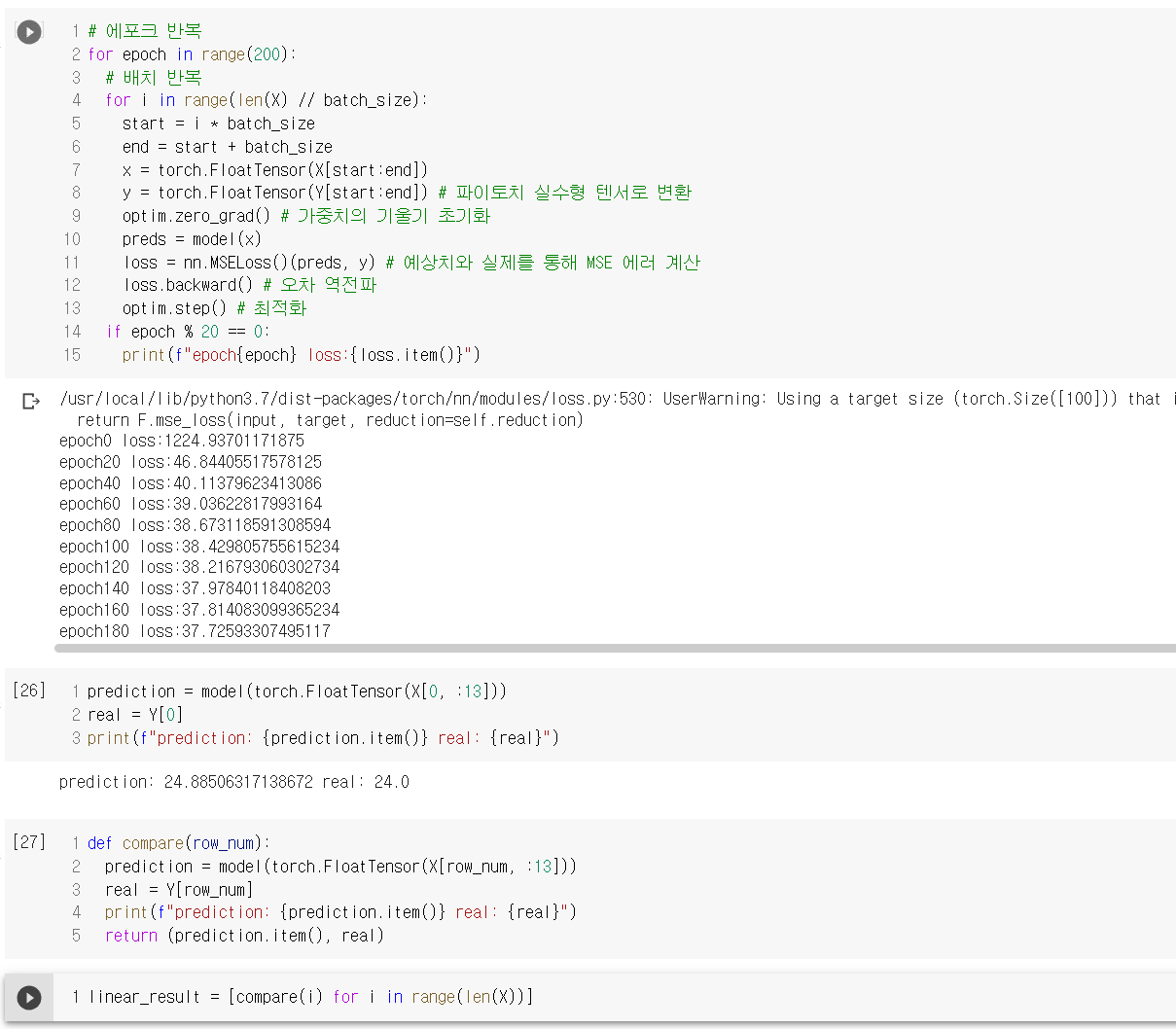
보스턴 집값 데이터 실습의 경우 예측이 잘 된 경우도 있었지만 잘 안 된 경우도 있었다. 이는 애초에 해당 데이터셋 자체가 선형 데이터가 아닌 점에서 기인한 것으로 보인다. 다른 학습 방법을 사용해서 실습해보아야 겠다.
3. 손글씨 데이터
또 다른 유명 데이터셋 중 하나인 손글씨 데이터를 통해서도 실습했다.
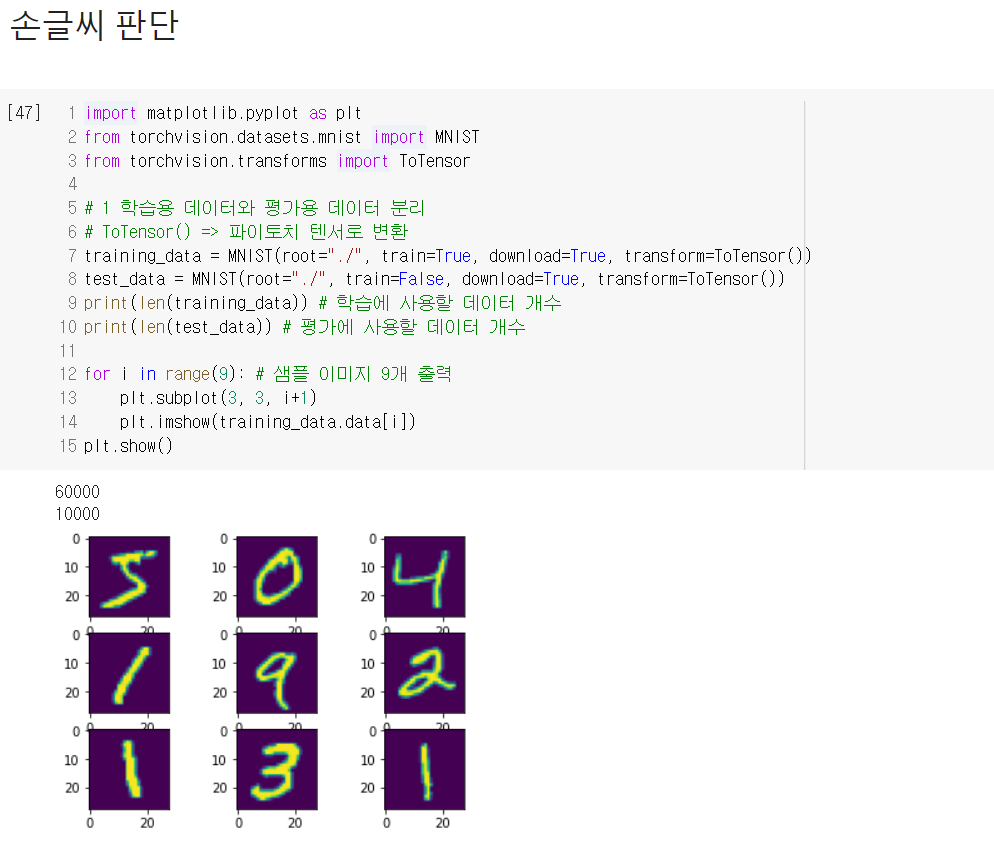

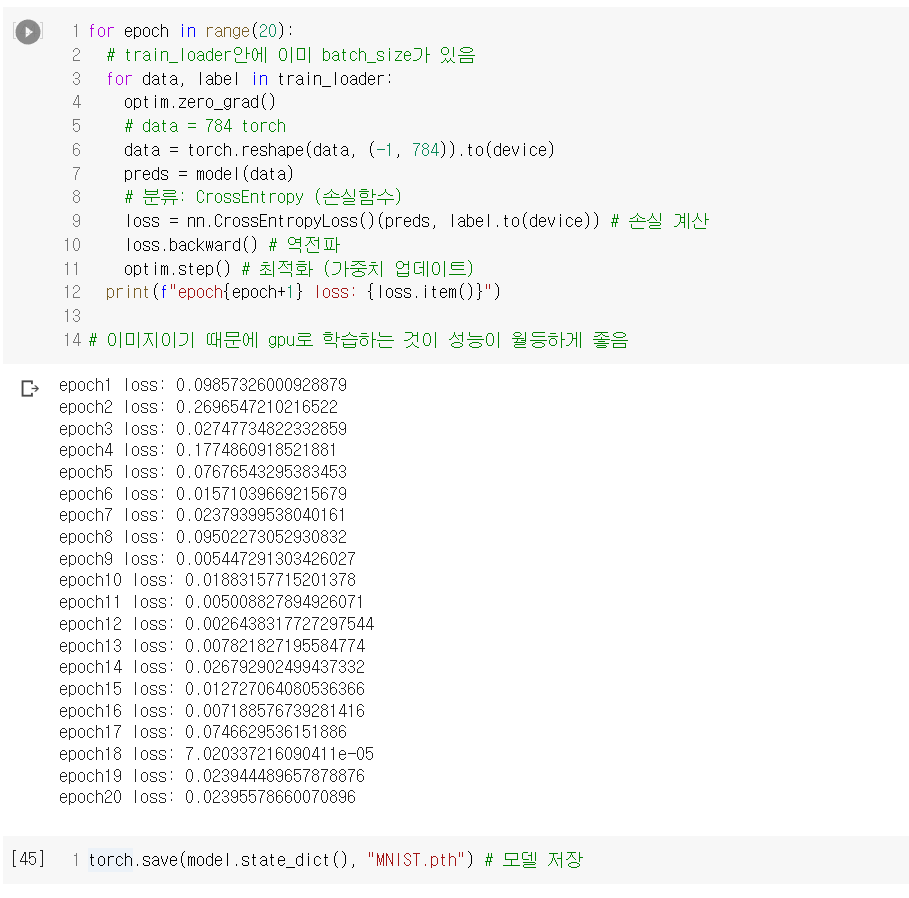

종합하자면, 딥러닝은 개념은 어렵지만 사용하는 것 자체는 개념에 비해 쉬운 것이라고 생각된다. 머신러닝에서의 XGBoost와 비슷하게 답을 내놓긴 하고 그것이 정답에 가깝긴 하지만 어떻게 답을 내놓았는지는 알 수 없는 느낌도 든다. 그렇기 때문에 물론 개념 공부도 중요하겠지만, 우선 사용에 좀 더 익숙해질 수 있도록 노력해야겠다.
이번 실습에서 사용한 데이터들은 이미 전처리가 되어 있는 상황이었지만, 실제 데이터 분석에서는 딥러닝을 사용해도 당연히 전처리가 필요하다는 점을 기억하자.
'Python' 카테고리의 다른 글
| Day 31 - 딥러닝 > U-Net & RNN (0) | 2022.11.22 |
|---|---|
| Day 29/30 - 딥러닝 > CNN (0) | 2022.11.21 |
| Day 27 - 머신러닝 9 > K 평균 군집화 (K-Means Clustering) (0) | 2022.11.16 |
| Day 26 - 머신러닝 8 > LightGBM (0) | 2022.11.15 |
| Day 26 - 머신러닝 7 > XGBoost (0) | 2022.11.15 |