Day 11 - Numpy (2)
2022. 10. 19. 17:12ㆍPython
이 글에서는 지난 글에 이어 파이썬의 라이브러리 중 하나인 numpy에 대해 계속해서 다룰 것이다.
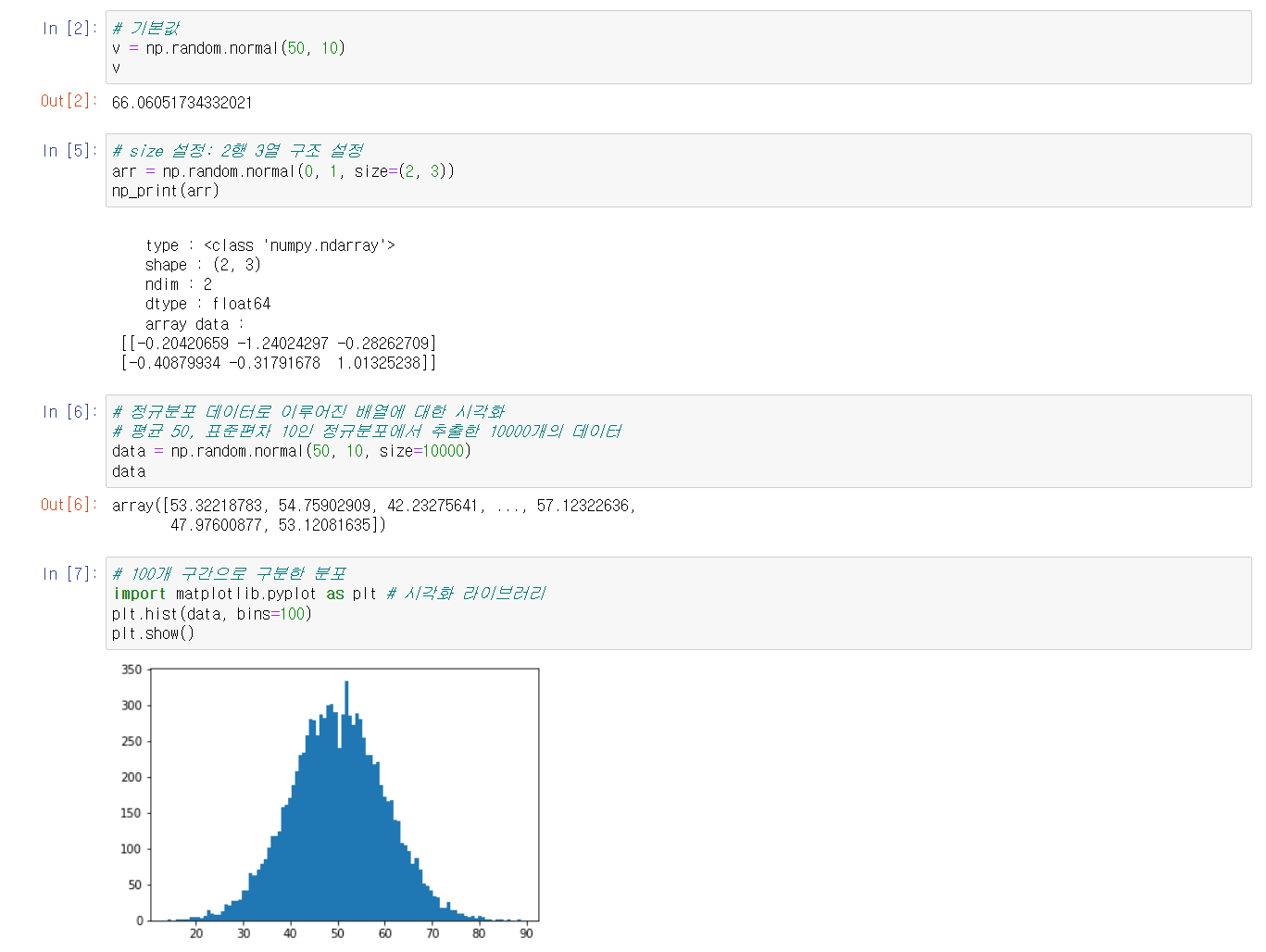
numpy의 배열 생성 방법 중 3번째는 난수를 데이터로 가지는 배열을 생성하는 것이다. 난수 배열 생성 함수에 정규분포 확률의 밀도에서 표본을 추출하는 함수가 있고, 또 정규분포는 데이터분석의 기본이기 때문에 정규분포와 분산, 표준편차에 대해 간략하게 공부하고 함수를 배웠다.

난수 데이터 배열 생성을 보다 이해하기 위해서는 프로그래밍에서의 난수에 대한 이해가 필요하다. 난수의 의미는 무작위의 수이지만, 실제 프로그래밍에서는 난수가 고정된 기준을 가지고 규칙적으로 생성된다. 따라서 난수의 시작점을 정해주면 동일한 난수를 생성할 수 있으며, np.random.seed()로 시작점을 설정할 수 있다.

seed함수를 직접 사용하여 시작점을 설정한 후 난수를 생성해보았다.

각 함수의 역할은 다음과 같다.
- np.random.normal(loc, scale, size): 정규분포 확률 밀도에서 표본을 추출하여 데이터로 가지는 배열을 생성한다. 각 인자는 평균, 표준편차, 배열구조를 의미하여 표준 정규분포를 따르기 위해 각 기본값은 0, 1이다.
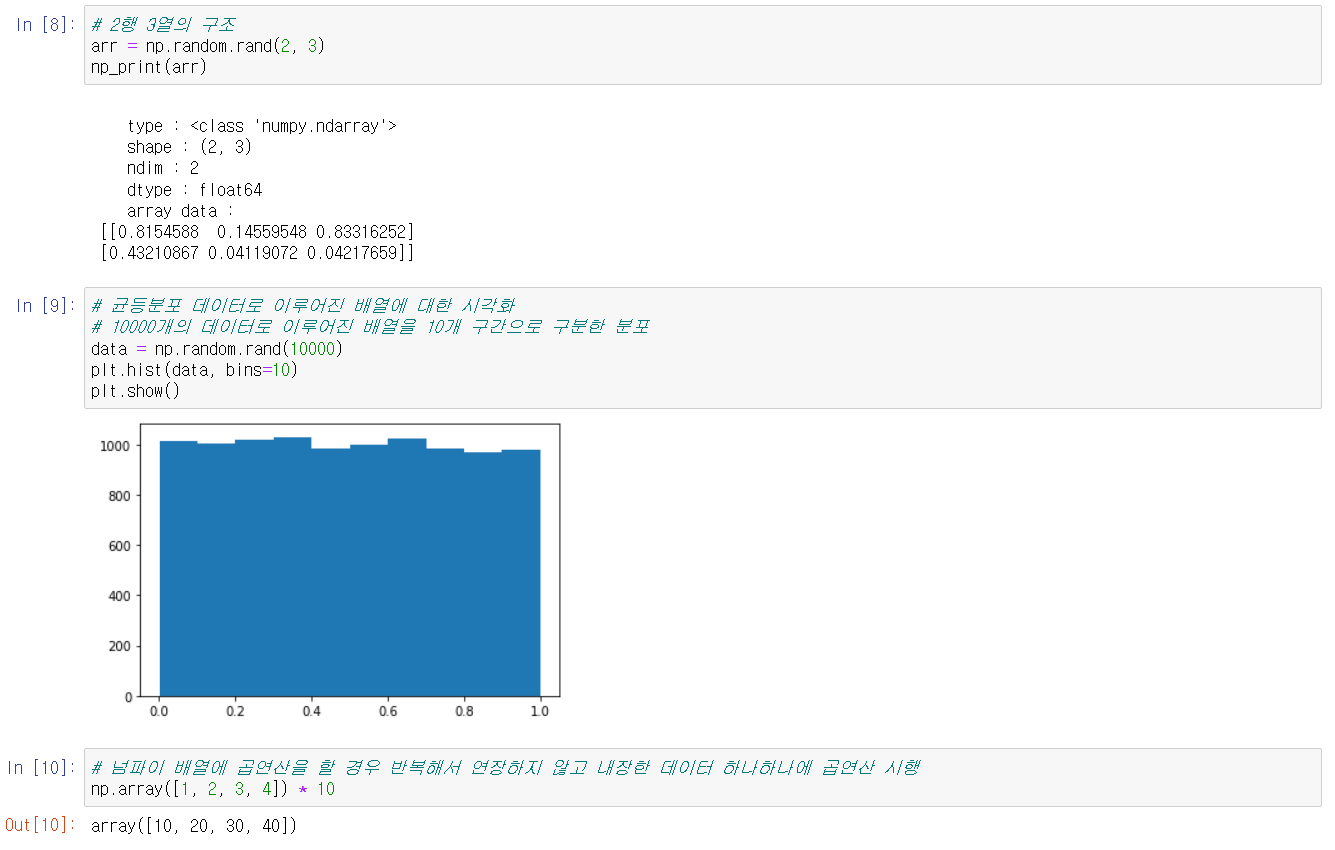
- np.random.rand(d0, d1, ..., dn): 지정한 구조로 배열을 생성한 후 난수로 초기화한다. 이때 난수는 0과 1사이의 범위에서 균등분포로 추출한다. 각 인자는 배열의 구조를 의미한다.
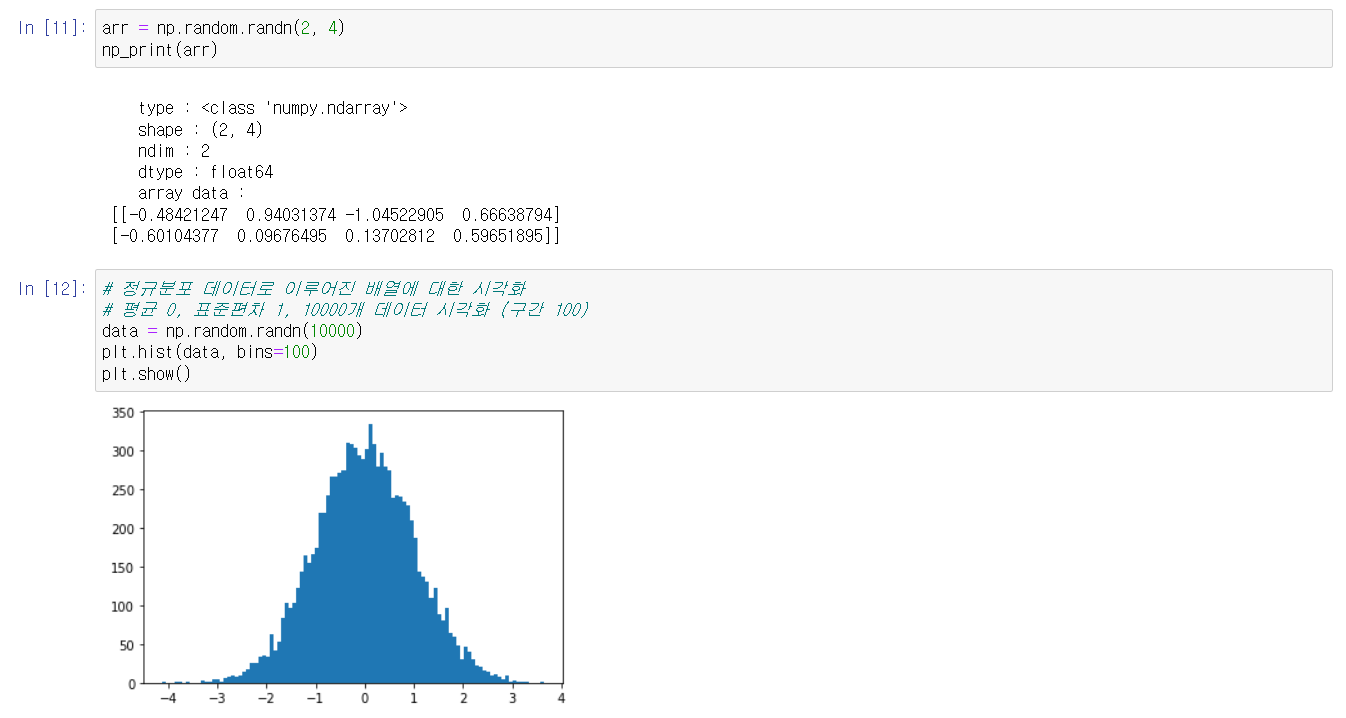
- np.random.randn(d0, d1, ..., dn): 지정한 구조로 배열을 생성한 후 난수로 초기화한다. 이때 난수는 표준 정규분포에서 추출된다. 위와 마찬가지로 각 인자는 배열의 구조를 의미한다.
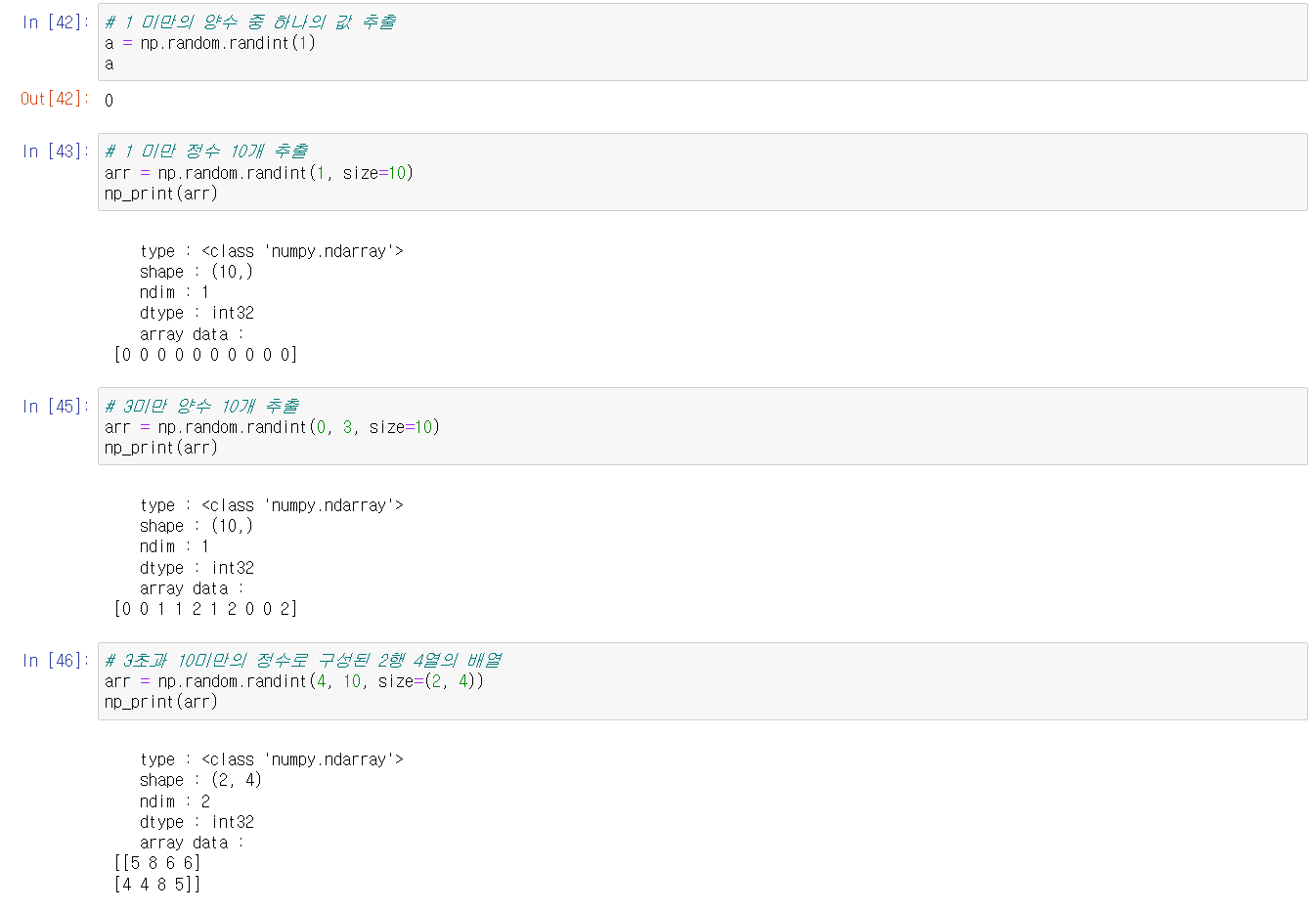
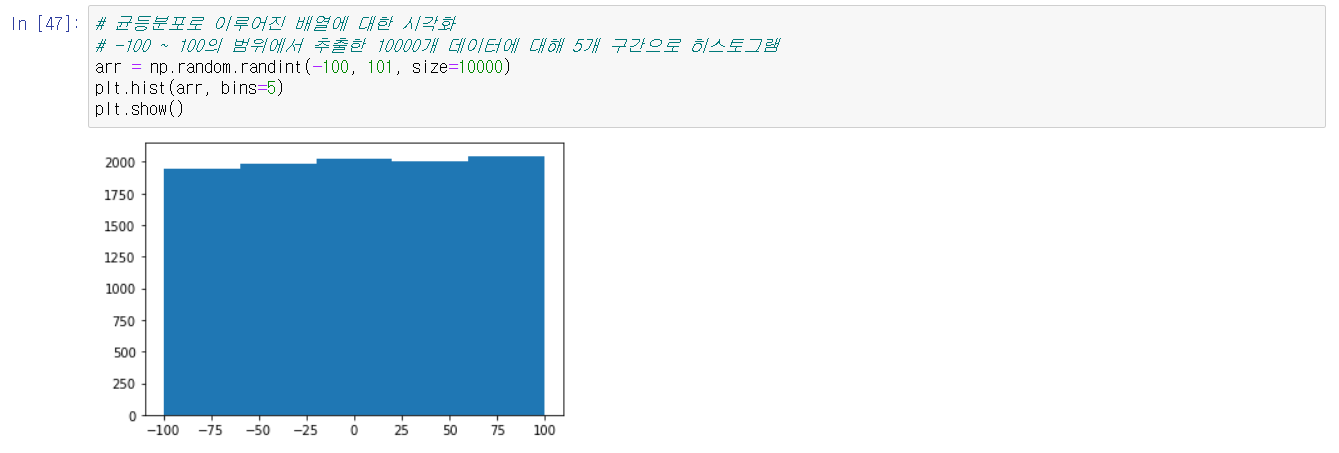
- np.random.randint(low, high, size, dtype): 지정한 범위 내에서 정수로 구성된 데이터를 가진 배열을 생성한다. 각 인자는 최소값, 최대값, 배열구조, 데이터타입을 의미한다. 여기서 high값이 지정되지 않으면 low값을 최대값으로 작동한다.




해당 함수들을 실습해보고, matploblib 라이브러리를 이용하여 히스토그램을 그려보았다. 이는 정규분포와 균등분포의 차이를 눈으로 확인하기 위해서이다.
'Python' 카테고리의 다른 글
| Day 12 - Numpy (4) (0) | 2022.10.20 |
|---|---|
| Day 11 - Numpy (3) (0) | 2022.10.19 |
| Day 10 - Numpy (0) | 2022.10.18 |
| Day 10 - 파이썬의 클래스 (4) (0) | 2022.10.18 |
| Day 9 - 파이썬의 클래스 (3) (0) | 2022.10.18 |