2022. 10. 6. 15:42ㆍPython
이번 글에서는 파이썬의 리스트 데이터타입에서 리스트 복사를 다룰 것이다.
하지만 리스트 복사를 다루기 이전에, 파이썬에서의 '기본형 데이터'와 '참조형 데이터'에 대한 이해가 필요하다.
기본형 데이터와 참조형 데이터를 이해하기 위해서는 기초적인 cpu 구조에 대해 이해할 필요가 있다. cpu 구조는 크게 3가지로 이루어져 있는데, 이중 시스템은 사용자가 통제할 수 없는 구조이다. 나머지 두 개의 구조인 스택과 힙의 경우에는 사용자가 어느 정도는 통제할 수 있다.
스택과 힙의 경우에는 상호 반대적인 장단점 때문에 상호보완적인 특성을 갖는다. 스택은 할당된 용량이 적은 단점이 있는 대신 데이터를 빠르게 찾을 수 있다는 장점이 있고, 힙은 할당된 용량이 크다는 장점이 있는 대신 데이터 탐색 속도가 상대적으로 느리다는 단점이 있다. 따라서 기본적으로 프로그래밍 시 데이터는 스택에 저장하게 되고, 이 스택의 용량이 적기 때문에 기본적으로는 하나의 변수에 하나의 데이터만 입력한다.
하지만 우리 모두 튜플이나 리스트, 혹은 데이터프레임처럼 파이썬에서 하나의 변수에 여러 데이터를 입력하는 경우가 있고, 심지어 굉장히 많이 쓴다는 것을 알고 있다. 그러나 이 데이터들을 모두 스택에 저장하는 경우 용량을 감당하지 못해 스택이 뻗어버리는 오버플로우 현상이 발생하기 때문에, 이를 방지하기 위한 방법을 고안했고 이것이 스택과 힙이 상호보완적인 관계라고 할 수 있는 이유인 주소 할당이다.
데이터는 기본적으로 스택에 저장하지만, 많은 양의 데이터가 한 변수에 있게 되면 해당 데이터는 힙에 저장하게 되고, 힙 내부의 어느 위치에 저장되어 있는지 파악하기 위해 각 데이터에 주소를 할당한다. 그리고 스택에는 해당 주소를 저장한다. 따라서, a라는 변수에 아이템이 10개 있는 리스트를 할당했다면, 리스트 내부의 데이터는 힙에 저장되는 것이다. 그리고 스택에는 힙에 저장된 데이터의 주소가 저장되어, 실제 a라는 변수에 저장되어 있는 데이터는 힙에 저장된 데이터에 할당된 주소라고 할 수 있다.
여기서 파이썬의 데이터는 크게 두 가지로 나눌 수 있음을 알 수 있다. 데이터의 양이 적어서 스택에 바로 저장되는 데이터는 기본형 데이터라고 하고, 데이터의 양이 많아서 데이터를 힙에 저장한 뒤 스택에는 해당 데이터가 저장된 위치를 저장하는 데이터는 참조형 데이터라고 한다. 이 두 가지 종류의 데이터에 대한 확실한 이해가 있어야 리스트의 복사 방법들, 그리고 아마도 데이터프레임과 튜플 등등 파이썬에서 사용하는 데이터들을 다루는 방법에 대한 이해가 편할 것이다.

위의 내용을 바탕으로, 리스트를 복사하는 방법 역시 크게 두 가지로 나눌 수 있다. 단순히 스택에 저장된 주소만 복사하는 얕은 복사와, 힙에 저장된 데이터를 직접 복사하는 깊은 복사가 그것이다.
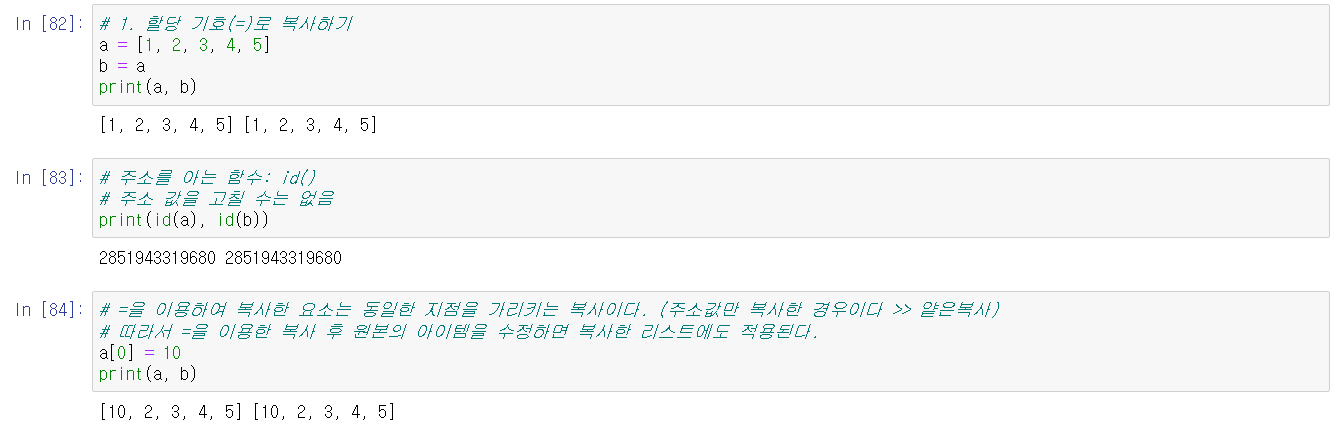
얕은 복사의 경우 스택에 저장된 주소만 복사하는 것이기 때문에, 원 리스트와 복사한 리스트 간 주소값이 같으며, 원 리스트에서 아이템을 수정할 경우 복사한 리스트에도 그대로 반영된다.
얇은 복사의 예시로는 =가 있다.
깊은 복사의 경우 힙에 저장된 데이터를 복사하여 새로운 주소에 할당하게 되고, 해당 변수에는 다른 주소를 저장하게 된다. 즉, 원 리스트와 복사한 리스트 간 주소값이 다르고, 원 리스트에서 아이템을 수정해도 복사한 리스트에는 반영되지 않는다.
깊은 복사의 예시로 copy()가 있다. 또한 list()나 슬라이싱 전체범위 지정을 이용한 복사의 경우에도 깊은 복사를 수행한다.

'Python' 카테고리의 다른 글
| Day 3 - 파이썬의 딕셔너리 데이터타입 (1) (0) | 2022.10.06 |
|---|---|
| Day 3 - 파이썬의 튜플 데이터타입 (0) | 2022.10.06 |
| Day 3 - 파이썬의 리스트 데이터타입 (3) (0) | 2022.10.06 |
| Day 3 - 파이썬의 리스트 데이터타입 (2) (0) | 2022.10.06 |
| Day 2 - 파이썬의 리스트 데이터타입 (0) | 2022.10.05 |